Chapter 4: Create a Website Bot to Scrape Specific Website Data Using BeautifulSoup
As mentioned in the last chapter about “How to Write, Parse, Read CSV Files with Scraped Data”, we would discuss how to specify web data to scrape, because this is one of the key purposes of why we like to learn Python as a digital marketer.
So in this python tutorial for digital marketers 4, I’ll walk you through a basic concept, and methods with using beautifulsoup and requests you need to know to specify web data and scrape. It’s better if you understand how to read HTML, CSS, javascript in this part, but it’s totally okay if you haven’t yet, because the purpose is to find the data located at the moment and learn some methods to scrape specific data for digital marketing purpose.
During the lesson, I’ll take Ring.com as an example to write codes and scrape all the latest offers and pricing. By the end of the lesson, you can master identify where your expected data locate on a target page and scrape it all in minutes.

As mentioned in the previous Chapter 3 about “How to Write, Parse, Read CSV Files with Scraped Data”, we would discuss how to specify web data to scrape. It’s because this is one of the key purposes of why we like to learn Python as a digital marketer.
So in this python tutorial for digital marketers 4, I’ll walk you through basic concepts, and methods. It’s with using Beautifulsoup and Requests you need to know to specify web data and scrape. It’s better if you understand how to read HTML, CSS, and javascript in this part. But it’s totally okay if you haven’t yet because the purpose is to find the data located at the moment. And also it’s for learning some methods to scrape specific data for digital marketing purposes.
During the Python tutorial lesson, I’ll take Ring.com as an example to write codes and scrape all the latest offers and pricing. By the end of the Python tutorial, you can identify where your expected data elements are on a page and scrape it all in minutes.
Table of Contents: Create a Website Bot to Scrape Specific Website Data Using BeautifulSoup
- Identify the data section on a target page
- Specify the data to parse and scrape
- Create a loop to scrape all section specified data
- Pass missing data in some sections
- Save the data into a CSV file
- Full Python Script of Website Bot
- FAQ
Identify the data section on a target page
As you can see here, there are many ring product bundles and offers that might be updated irregularly. If you were a Ring reseller or Ring’s competitor, you definitely like to adjust the product marketing and pricing strategy, in order that the conversion rate will not be impacted if sales are critical for your business.

To find the data location, we need to use a browser developer tool and inspect the web source code. I take Chrome as an example, you can select a product and right-click to select inspect.

We aim to scrape data from headlines, subheadlines, regular prices, promotion prices, descriptions, and product URLs. Based on this data scraping target, we try to look into the code and find out this section or what we call division, which includes all the data we target to scrape:
<div class=”plp-product”.......</div>
You are aware of the resting of product information all start with the same division:
<div class=”plp-product”.......</div>
To see if this is correct, we can start using methods: find(), and find_all()
(Note: I’m not going into details on how to import Beautifulsoup, requests modules. If you like to learn more, please check the previous articles:
Chapter 2: Web Scraping with BeautifulSoup, Requests, Python
Web Scraping – Find and Find All Function
First of all, let us create variables called ringweb, ringoffers and ringproduct
ringweb = requests.get('https://ring.com/collections/offers').text
ringoffers = BeautifulSoup(ringweb,'lxml')
find() method is used to locate your scraping action and get a response of the data from this location. As the path is, <div class=”plp-product”.......</div>so we can write a line of code
ringproduct = ringoffers.find('div', class_='plp-product')
In this line of code, we define a variable, ringrproductwhich represents the data of the target path under ringoffers. Just keep in mind, that in the Python method, we usually use commas to split the HTML source code and use single quotes for each source code. Regarding class, we need to use class_=, because class= stands for the other function in Python.
If we try to print this out and command B, you can see these lines of code can grab the section data already. It’s working.
As Ring.com has not only one set of bundles to sell on the offer page, so we need to use the other method find_all(). We only need to replace find() with find_all(), you can see all bundle section data are generated.

Specify the data to parse and scrape
Now we start to parse the target section data and specific data we want to scrape, as we mentioned earlier in this article.
First of all, it’s the product headline
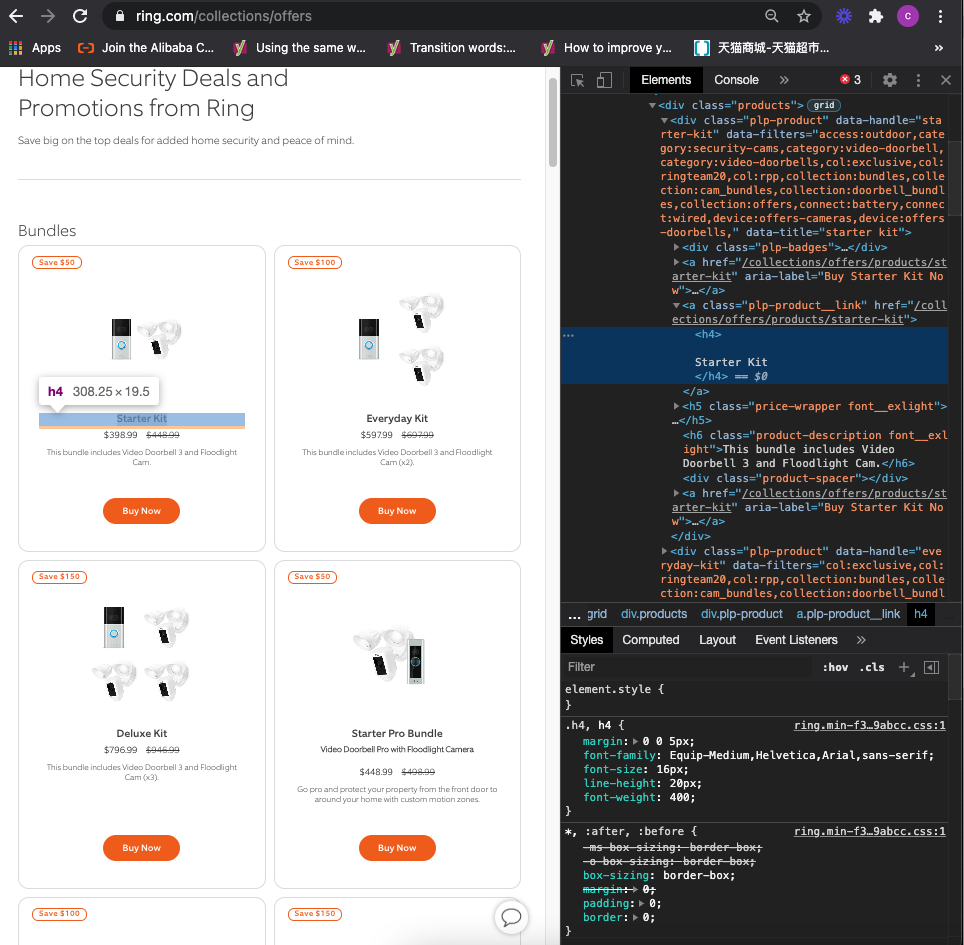
We can inspect and see from developer tools, Ring offers page h4 only represents the bundle products’ headline, so we can directly write a line of code:
headline = ringproduct.h4.text
print(headline)
In Python, we split a path by using a dot except for a path within a method. As we scrape the string data, so we can use text after h4.
Then, its subheadline and description

We can see there are two places that are using h6 (subheadline and description). So different from the headline, we need to use find() method and locate a specific h6 data
subheadline = ringproduct.find('h6', class_='sub-title size-xs').text
print(subheadline)
description = ringproduct.find('h6',class_='product-description font__exlight').text
print(description)
You would find out not all the product bundles have subheadlines. In Python, we need to pass missing data in order to avoid errors in running the script file. I’ll talk about it in a moment.
Then, it’s the regular price and promotion price

promote_price = ringproduct.find('span',class_='regular-price').text
print(promote_price)
regular_price = ringproduct.find('span',class_='compare-price').text
print(regular_price)
Last but not least, it’s the product landing URL

Lines of code:
product_url = ringproduct.a['href']
product_link = f'https://ring.com{product_url}'
print(product_link)
Basically, there’s only one unique URL showing in the source code of each product bundle. For example, the product starter kit landing path is collections/offers/products/starter-kit. So we could ignore which value we aim to scrape and directly leverage [ ], to scrape href value in a section: product_url = ringproduct.a['href']
However, if we scrape these data paths into a file, they can’t be opened and accessed on the page. So for displaying the full URL, we can create a variable product_link and leverage the format feature by using f ‘’ and insert product_url into { }.
product_link = f'https://ring.com{product_url}’
If we try to print this out, we can have a result that proves it’s working.

Create a loop to scrape all section-specified data
These lines of code are working so that we can roll it out to scrape all data in bulk. For this, we need to use for…in and find_all methods:
for ringproduct in ringoffers.find_all('div', class_='plp-product'):
As this code is on the parent level, so we need to add a colon at the end of this line of code and indent children lines.
If we try to print this out, we can see the result listed below, which includes all product bundle information.
Pass missing data in some sections
You might be aware that not all product bundles have subheadline and promotion price, so if you try to run subheadline and promotion price lines of code if you come across this response from Python: object has no attribute ‘text’, and it would stop the scraping process.

This is the reflection of the coding world because not all information is in order and structured. So we need to use try/except to pass this when coming across.
Subheading:
try:
subheadline = ringproduct.find('h6', class_='sub-title size-xs').text
except Exception as e:
subheadline = None
Promotion price:
try:
regular_price = ringproduct.find('span',class_='compare-price').text
except Exception as e:
regular_price = None
For the variable value under except exception as e, you can set it as you feel it’s easy to understand, such as none, 0, ‘NA’, etc.
I set none, so you can see the response result

Save the data into a CSV file
Now the python script is ready, and it’s time to save the scraped data into a place, which can be either a local file or an online server.
I’m going to go into details about the CSV file because I talked about this lesson previously. If you are interested, please check out the other article
Chapter 3: Utilise CSV Module to Write, Parse, Read CSV Files to Manage Scraped Data
After the codes are done, a CSV file like the one below would come up and store all specified data we aim to scrape.

Full Python Script of Website Bot
If you would like to have the full version of the Python Script of Website Bot, please subscribe to our newsletter by adding the message Chapter 4. We would send you the script immediately to your mailbox.
So easy, right? I hope you enjoy reading Chapter 4: Create a Website Bot to Scrape Specific Website Data Using BeautifulSoup. If you did, please support us by doing one of the things listed below, because it always helps out our channel.
- Support and donate to our channel through PayPal (paypal.me/Easy2digital)
- Subscribe to my channel and turn on the notification bell Easy2Digital Youtube channel.
- Follow and like my page Easy2Digital Facebook page
- Share the article on your social network with the hashtag #easy2digital
- Buy products with Easy2Digital 10% OFF Discount code (Easy2DigitalNewBuyers2021)
- You sign up for our weekly newsletter to receive Easy2Digital latest articles, videos, and discount codes
- Subscribe to our monthly membership through Patreon to enjoy exclusive benefits (www.patreon.com/louisludigital)
Apart from scraping HTML and XML web data, if you are interested in learning to fetch some platform data which can only be accessed via API, please check out this article, and we would start with the Youtube channel.
Chapter 5 – Build a Youtube Bot to Scrape Trending Videos Using Youtube and Easy2Digital APIs
FAQ:
Q1: What is the Web Bot?
A: The Web Bot is a brand product that is designed to improve the SEO of e-commerce websites.
Q2: How does the Web Bot work?
A: The Web Bot uses advanced algorithms to analyze the content and structure of e-commerce websites, and then provides recommendations for optimizing the SEO.
Q3: What are the benefits of using the Web Bot?
A: Using the Web Bot can help improve the search engine rankings of e-commerce websites, increase organic traffic, and ultimately drive more sales.
Q4: Can the Web Bot be used for any e-commerce platform?
A: Yes, the Web Bot is compatible with all major e-commerce platforms, such as Shopify, WooCommerce, Magento, and more.
Q5: Is the Web Bot easy to use?
A: Yes, the Web Bot has a user-friendly interface and does not require any technical expertise. It is designed to be accessible for both beginners and experienced users.
Q6: How often should the Web Bot be used?
A: It is recommended to use the Web Bot regularly to ensure that your e-commerce website is constantly optimized for SEO. The frequency can vary depending on the size and complexity of your website.
Q7: Can the Web Bot help with keyword research?
A: Yes, the Web Bot has a built-in keyword research tool that can help you identify the most relevant and high-ranking keywords for your e-commerce website.
Q8: Does the Web Bot provide competitor analysis?
A: Yes, the Web Bot can analyze the SEO strategies of your competitors and provide insights on how to outperform them in search engine rankings.
Q9: Is the Web Bot compatible with other SEO tools?
A: Yes, the Web Bot can be integrated with other SEO tools to enhance your e-commerce website’s optimization and performance.
Q10: Can the Web Bot track the progress of SEO improvements?
A: Yes, the Web Bot provides detailed reports and analytics to track the progress of your SEO efforts and measure the impact on your e-commerce website’s performance.


