En este artículo, le explicaré brevemente cómo predecir una variante de precio basándose en haber considerado múltiples variables que podrían estar correlacionadas con el cambio de precio. Al final de este artículo, puede aplicar este módulo a casos reales de su empresa utilizando Python y Scikit learn para generar una puntuación para predecir los precios.
Ingredientes para preparar con anticipación: Numpy, Pandas, Scikit learn, matplotlib, seaborn, Linear Regression, StandardScaler, RandomForest
Tablas de contenido: una predicción de precios variantes basada en múltiples variables usando Python, ScikitLearn
Cargando conjunto de datos
Este artículo utiliza como ejemplo el conjunto de datos sobre precios de la vivienda de California. Dicho esto, puede utilizar los datos de su caso de negocio como conjunto de datos. Solo asegúrese de que el conjunto de datos tenga una cierta cantidad de datos que sea mejor para predecir la puntuación.
Como de costumbre, podemos usar Pandas para cargar el conjunto de datos y aplicar info() para echar un vistazo a las condiciones del conjunto de datos.
Para una mejor predicción, uno de los principios fundamentales es que el tamaño de los datos entre diferentes métricas debe tener la misma cantidad de filas de datos. Como puede ver en este ejemplo, obviamente las métricas de totle_bedrooms muestran algo de NA en su columna. Por lo tanto, primero debemos abandonar la NA.
data.dropna ( inplace= True )
Exploración de datos
Lo primero es establecer una variante objetivo para predecir. En este caso, el valor medio de la vivienda es la variante objetivo porque básicamente este experimento es para la toma de decisiones de compra de propiedades. Por lo tanto, debemos eliminar la métrica de la tabla existente y establecer la variante de destino por separado como una nueva variable en el script.
X = data.drop ([ 'median_house_value' ], axis= 1 )
y = data [ 'median_house_value' ]
Luego, podríamos intentar explorar la correlación de cada variable con nuestra variante objetivo y tener una idea general de si el conjunto de datos tiene sentido.
Generalmente no necesitamos utilizar todo el conjunto de datos para cumplir este propósito. En este caso, podemos nuevamente aprovechar la división de pruebas de trenes. Desarrollamos este método en el capítulo anterior. Si está interesado, explore otros capítulos en Easy2Digital.com
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size= 0.2 )
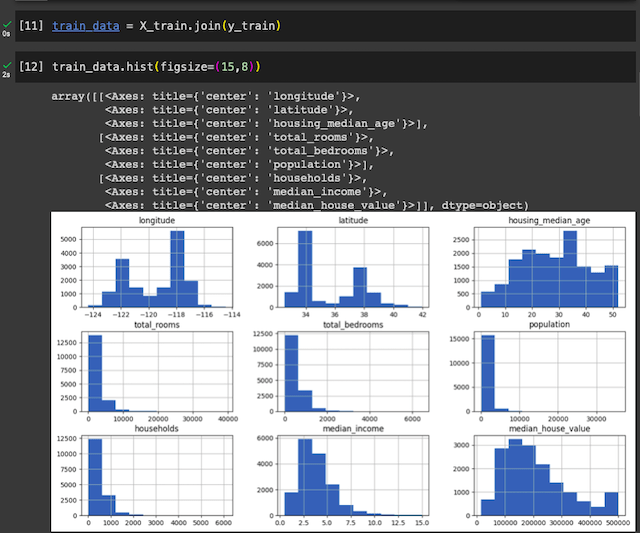
Luego, podemos intentar mostrarlos en el gráfico del histograma usando el método join() y hist().
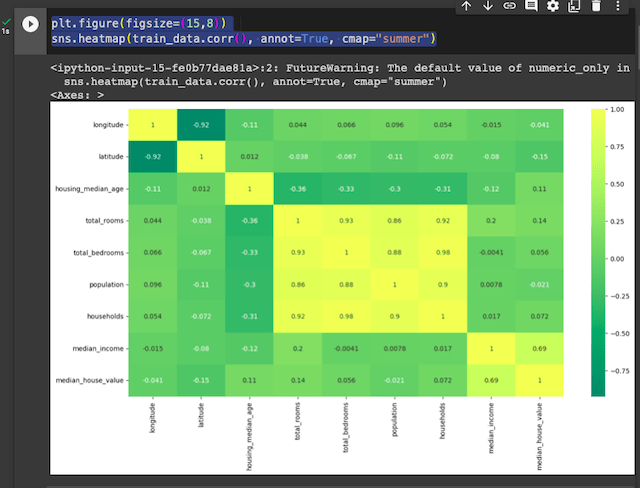
O podemos mostrarlo en un mapa de calor usando el método corr(), que es más visual con un contraste de color claro y profundo.
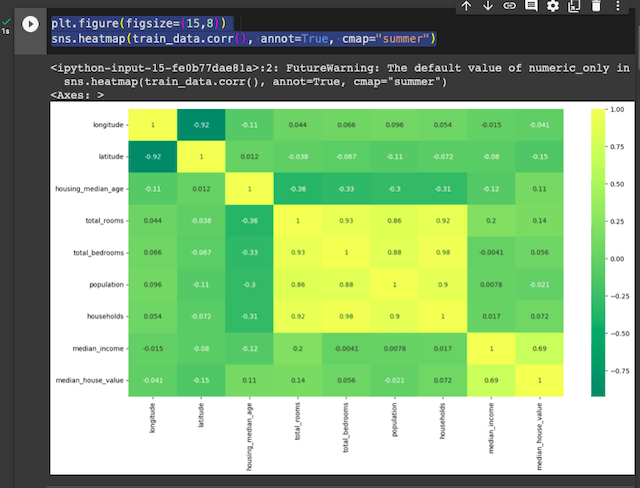
Preprocesamiento de datos
Podemos ver un montón de variables destacadas. Además, cuando observamos la distribución del histograma anterior, algunas características parecen no sensatas. Entonces podríamos intentar usar log() para ver si la distribución de variables destacadas puede ser mejor.
train_data [ 'total_rooms' ] = np.log ( train_data [ 'total_rooms' ] + 1 )
train_data [ 'total_bedrooms' ] = np.log ( train_data [ 'total_bedrooms' ] + 1 )
train_data [ 'population' ] = np.log ( train_data [ 'population' ] + 1 )
train_data [ 'households' ] = np.log ( train_data [ 'households' ] + 1 )
Tiene más sentido después de haber implementado el método de registro en este caso. Necesitamos agregar uno en el registro porque es en caso de que algunas de las características sean cero.
Luego, la otra sección crítica del preprocesamiento de datos es convertir el tipo de datos de cadena en números enteros. Esto se debe a que el aprendizaje automático es un proceso impulsado por números y no puede manejar cadenas directamente.
En el conjunto de datos, encontramos que la proximidad del océano está en el formato de tipo de datos de cadena. Por lo tanto, podemos usar el método panda get_dummies para manejar esto.
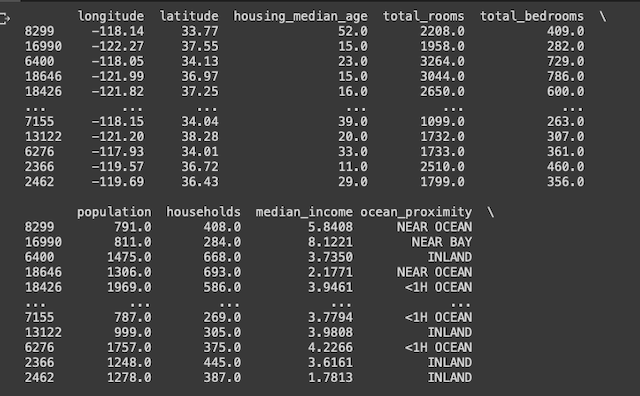
pd.get_dummies ( train_data.ocean_proximity )
Predecir utilizando el modelo de regresión lineal
Ahora el conjunto de datos está en su lugar y podemos intentar importar un modelo y probar la precisión del modelo para predecir el valor de la vivienda escalando el conjunto de datos de características.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler ()
X_train , y. _train = train_data.drop ([ 'median_house_value' ], axis= 1 ), train_data [ 'median_house_value' ]
X_train_s = scaler.fit_transform ( X_train )
reg = LinearRegression ()
reg.fit ( X_train_s , y_train )
LinearRegression ()
test_data = X_test.join ( y_test )
test_data [ 'total_rooms' ] = np.log ( test_data [ 'total_rooms' ] + 1 )
test_data [ 'total_bedrooms' ] = np.log ( test_data [ 'total_bedrooms' ] + 1 )
test_data [ 'population' ] = np.log ( test_data [ 'population' ] + 1 )
test_data [ 'households' ] = np.log ( test_data [ 'households' ] + 1 )
test_data = test_data.join ( pd.get_dummies ( test_data.ocean_proximity )) .drop ([ 'ocean_proximity' ], axis= 1 )
X_test , y_test = test. _data.drop ([ 'median_house_value' ], axis= 1 ), test_data [ 'median_house_value' ]
X_test_s = scaler.transform ( X_test )
reg.score ( X_test_s , y_test )
Script completo de Python para construir un modelo de predicción de precios basado en múltiples variables usando Python, ScikitLearn
Si está interesado en crear un modelo de predicción de precios utilizando Python, ScikitLearn, regresión lineal, suscríbase a nuestro boletín agregando el mensaje 'modelo de predicción de precios' . Le enviaremos el script inmediatamente a su buzón de correo.
Espero que disfrute leyendo Cree un modelo de predicción de precios utilizando Python, ScikitLearn y regresión lineal. Si lo hizo, apóyenos haciendo una de las cosas que se enumeran a continuación, porque siempre ayuda a nuestro canal.
Recomendación del curso Coursea sobre ciencia de datos y aprendizaje automático
