
El algoritmo de bosque aleatorio se ha aplicado en varias industrias, lo que les permite tomar mejores decisiones comerciales. Algunos casos de uso incluyen análisis de alto riesgo crediticio y recomendación de productos para fines de venta cruzada.
En este artículo, lo guiaré brevemente a través de varios métodos para generar la importancia de las características mediante el uso de un conjunto de datos de validación de calidad del vino tinto clásico. Al final de este capítulo, podrá tener un concepto básico para utilizar el bosque aleatorio aplicado a sus proyectos y comparar el resultado entre diferentes métodos.
Tabla de contenido: Genere la importancia de las características del objeto utilizando Scikit learn y Random Forest en el aprendizaje automático
División del conjunto de datos de vino tinto y entrenamiento de datos
Para cualquier modelo de aprendizaje automático, es fundamental obtener un conjunto de datos adecuado o preprocesar los datos. Kaggle es una de las plataformas más populares para buscar un conjunto de datos adecuado. Aquí tenéis el enlace del proyecto de calidad del vino tinto.
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
Lo primero es procesar los datos usando Pandas y Sklearn train_test_split es el primer paso.
url = "winequality-red.csv"
wine_data = pd . read_csv ( url , sep = ";" )
x = wine_data . drop ( 'quality' , axis = 1 )
y = wine_data [ 'quality' ]
x_train , x_test , y_train , y_test = train_test_split ( x , y , test_size = 0.5 , random_state = 50 )
Importancia de las funciones integradas con Scikit-learn
Scikit-learn proporciona un método de importancia de características integrado para modelos de bosque aleatorio. Según la documentación, este método se basa en la disminución de las impurezas de los nodos.
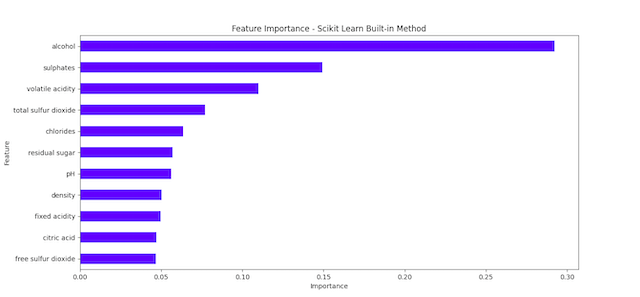
En un bosque aleatorio, las preguntas son como las características del modelo. Algunas preguntas te ayudan a eliminar más posibilidades que otras. Se supone que las características que le ayudan a eliminar más posibilidades rápidamente son más importantes porque le ayudan a acercarse más rápidamente a la respuesta correcta. Es muy sencillo obtener estas características importantes con Scikit-learn:
rf = RandomForestRegressor ( n_estimators = 100 , random_state = 50 )
rf . fit ( x_train , y_train )
inbuilt_importances = pd . Series ( rf . feature_importances_ , index = x_train .columns)
inbuilt_importances . sort_values ( ascending = True , inplace = True )
inbuilt_importances . plot . barh ( color = 'black' )
Método Scikit-learn integrado con una función aleatoria
La forma más sencilla de avanzar en este método es agregar una característica aleatoria al conjunto de datos y ver si el resultado puede desviarse más que el primero sin aleatoriedad.
Si una característica real tiene menor importancia que la característica aleatoria, podría indicar que su importancia se debe simplemente al azar.
def randomMethod ():
X_train_random = x_train .copy()
X_train_random [ "RANDOM" ] = np . random . RandomState ( 42 ). randn ( x_train .shape[ 0 ])
rf_random = RandomForestRegressor ( n_estimators = 100 , random_state = 42 )
rf_random . fit ( X_train_random , y_train )
importances_random = pd . Series ( rf_random . feature_importances_ , index = X_train_random .columns)
importances_random . sort_values ( ascending = True , inplace = True )
importances_random . plot . barh ( color = 'blue' )
plt . xlabel ( "Importance" )
plt . ylabel ( "Feature" )
plt . title ( "Feature Importance - Scikit Learn Built-in with random" )
plt . show ()
return
Importancia de la característica de permutación
La importancia de la característica de permutación es otra técnica para estimar la importancia de cada característica en un modelo de bosque aleatorio midiendo el cambio en el rendimiento del modelo cuando los valores de la característica se mezclan aleatoriamente.
Una de las ventajas de este método es que se puede utilizar con cualquier modelo, no solo con Random Forests, lo que hace que los resultados entre modelos sean más comparables.
Importancia de las características del bosque aleatorio con SNAP
SHAP es un método para interpretar el resultado de modelos de aprendizaje automático basado en la teoría de juegos.
Proporciona una medida unificada de la importancia de las características que, al igual que la importancia de la permutación, se puede aplicar a cualquier modelo.
El principal inconveniente es que puede resultar costoso desde el. punto de vista computacional, especialmente para grandes conjuntos de datos o modelos complejos.
Importancia de la característica del camino forestal aleatorio
Otra forma de comprender cómo contribuye cada característica a las predicciones de Random Forest es observar las rutas del árbol de decisiones que toma cada instancia.
Calcula la diferencia entre el valor de predicción en el nodo hoja y los valores de predicción en los nodos que lo preceden para obtener la contribución estimada de cada característica.
Script completo de Python del generador de importancia de características
Si está interesado en el Capítulo 76: Generar la importancia de la característica del objeto utilizando Scikit learn y Random Forest, suscríbase a nuestro boletín agregando el mensaje 'Capítulo 75 + noción api' . Le enviaremos el script inmediatamente a su buzón de correo.
Espero que disfrute leyendo el Capítulo 76: Generar la importancia de las características del objeto utilizando Scikit learn y Random Forest. Si lo hizo, apóyenos haciendo una de las cosas que se enumeran a continuación, porque siempre ayuda a nuestro canal.
Recomendación del curso Coursea sobre ciencia de datos y aprendizaje automático
