
As mentioned in the previous Chapter 3 about “How to Write, Parse, Read CSV Files with Scraped Data”, we would discuss how to specify web data to scrape. It’s because this is one of the key purposes of why we like to learn Python as a digital marketer.
Entonces, en este tutorial de Python para los vendedores digitales 4, lo guiaré a través de conceptos y métodos básicos. Es con el uso de BeautifulSoup y las solicitudes que necesita saber para especificar datos web y raspado. Es mejor si comprende cómo leer HTML, CSS y JavaScript en esta parte. Pero está totalmente bien si aún no lo ha hecho porque el propósito es encontrar los datos ubicados en este momento. Y también es para aprender algunos métodos para raspar datos específicos para fines de marketing digital.
Durante la lección del tutorial de Python, tomaré Ring.com como ejemplo para escribir códigos y raspar las últimas ofertas y precios. Al final del tutorial de Python, puede identificar dónde están sus elementos de datos esperados en una página y rasparlo todo en minutos.
Tabla de contenido: cree un bote de sitio web para raspar datos específicos del sitio web utilizando BeautifulSoup
Identificar la sección de datos en una página de destino
Como puede ver aquí, hay muchos paquetes de productos de anillo y ofertas que pueden actualizarse de manera irregular. Si era un revendedor de anillo o el competidor de Ring, definitivamente le gusta ajustar la estrategia de marketing y precios de productos, para que la tasa de conversión no se vea afectada si las ventas son críticas para su negocio.
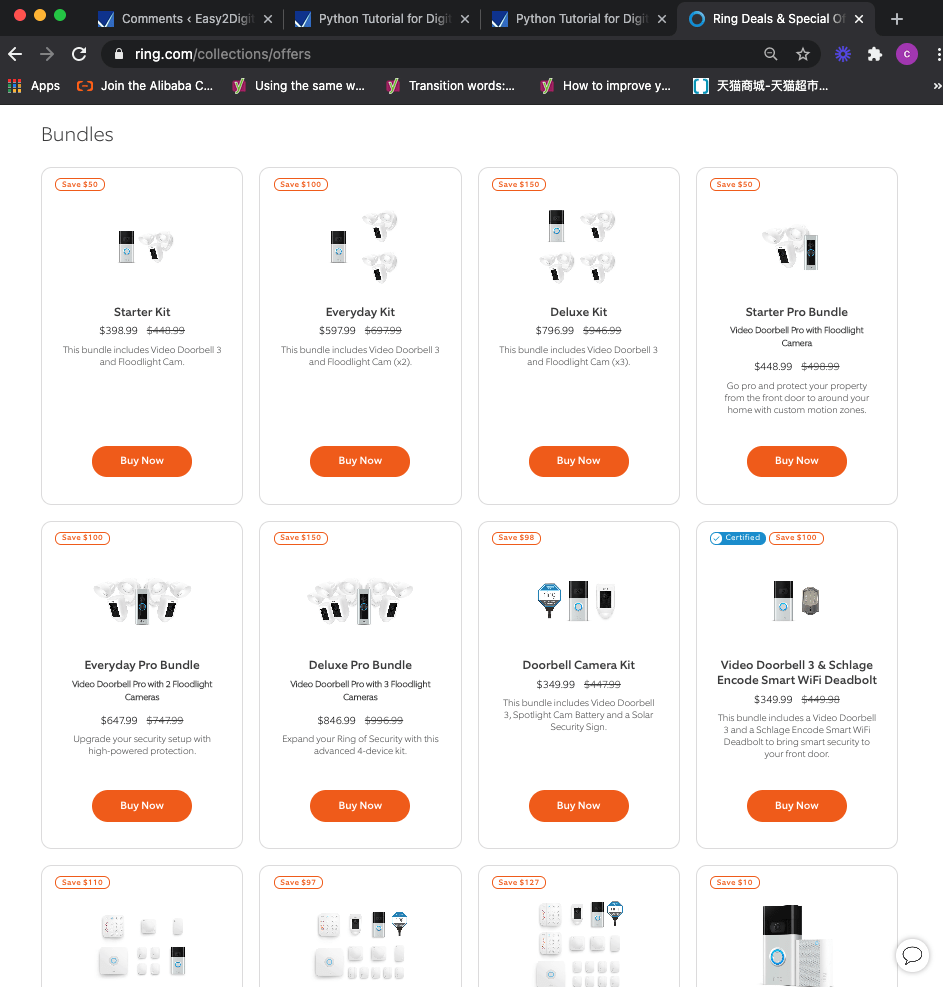
To find the data location, we need to use a browser developer tool and inspect the web source code. I take Chrome as an example, you can select a product and right-click to select inspect.
Nuestro objetivo es raspar datos de los titulares, subterráneos, precios regulares, precios de promoción, descripciones y URL de productos. Según este objetivo de raspado de datos, intentamos investigar el código y descubrir esta sección o lo que llamamos división, que incluye todos los datos que apuntamos a raspar:
<div class=”plp-product”.......</div>
Usted es consciente del descanso de la información del producto, todos comienzan con la misma división:
<div class=”plp-product”.......</div>
To see if this is correct, we can start using methods: find(), and find_all()
(Nota: no voy a entrar en detalles sobre cómo importar beautifulsoup, módulos de solicitudes. Si desea obtener más información, consulte los artículos anteriores:
Capítulo 2: Raspado web con Beautifulsoup, solicitudes, Python
Rastreo web: busque y busque toda la función
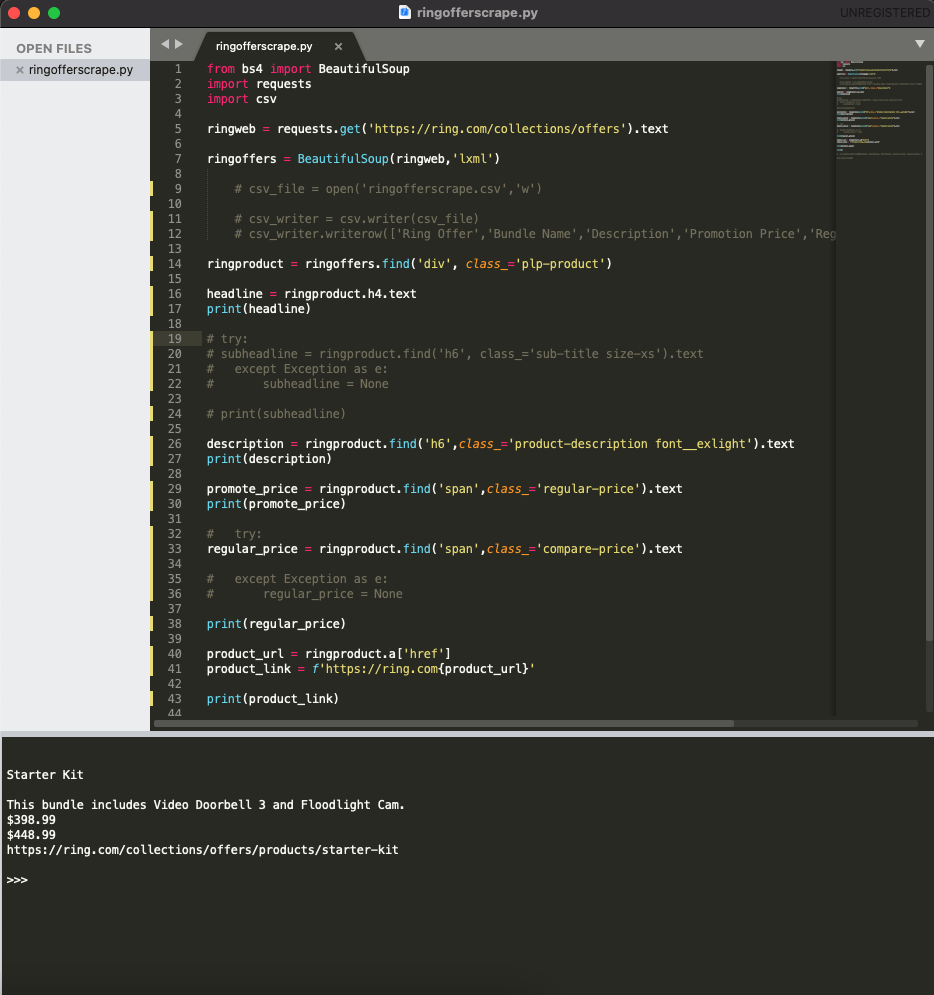
First of all, let us create variables called ringweb, ringoffers and ringproduct
ringweb = requests.get('https://ring.com/collections/offers').text
ringoffers = BeautifulSoup(ringweb,'lxml')
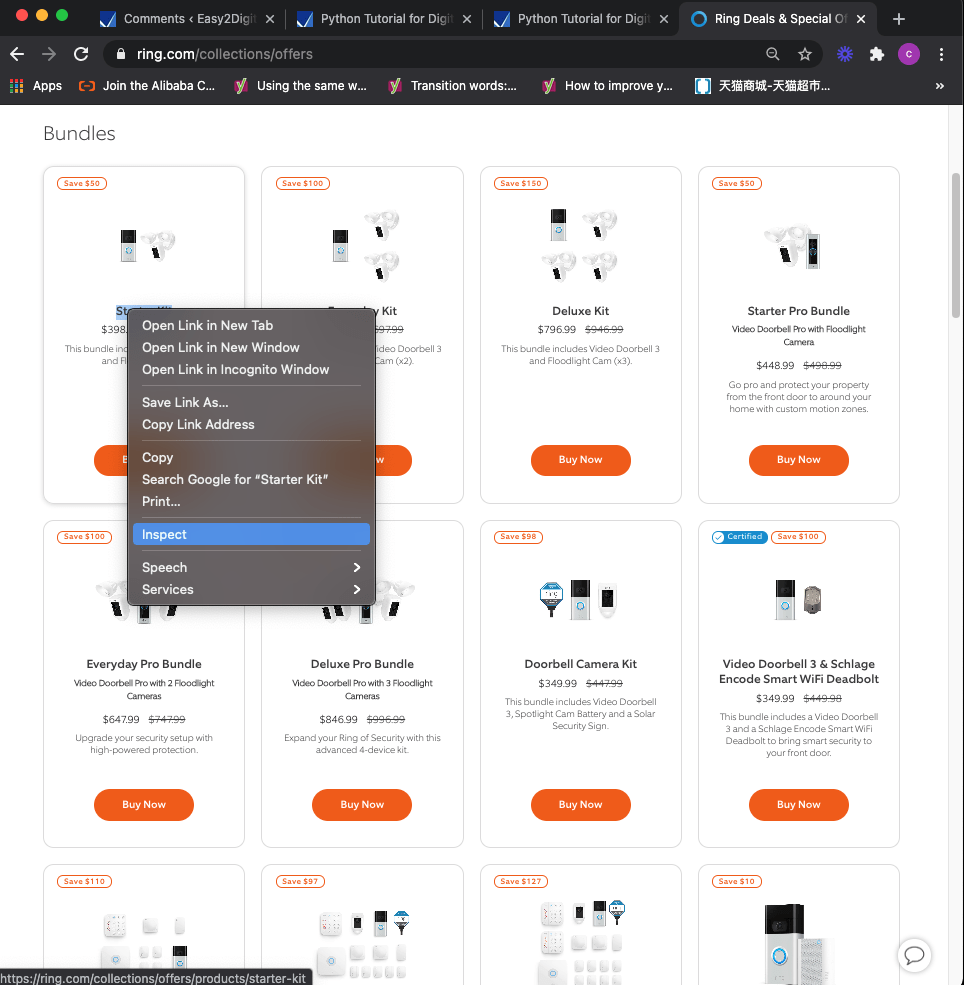
find() method is used to locate your scraping action and get a response of the data from this location. As the path is, <div class=”plp-product”.......</div>so we can write a line of code
ringproduct = ringoffers.find('div', class_='plp-product')
In this line of code, we define a variable, ringrproductwhich represents the data of the target path under ringoffers. Just keep in mind, that in the Python method, we usually use commas to split the HTML source code and use single quotes for each source code. Regarding class, we need to use class_=, because class= stands for the other function in Python.
Si intentamos imprimir esto y el comando B, puede ver que estas líneas de código ya pueden obtener los datos de la sección. Esta funcionando.
Como Ring.com no solo tiene un conjunto de paquetes para vender en la página de ofertas, por lo que necesitamos usar el otro método Find_All (). Solo necesitamos reemplazar find () con find_all (), puede ver que se generan todos los datos de la sección del paquete.
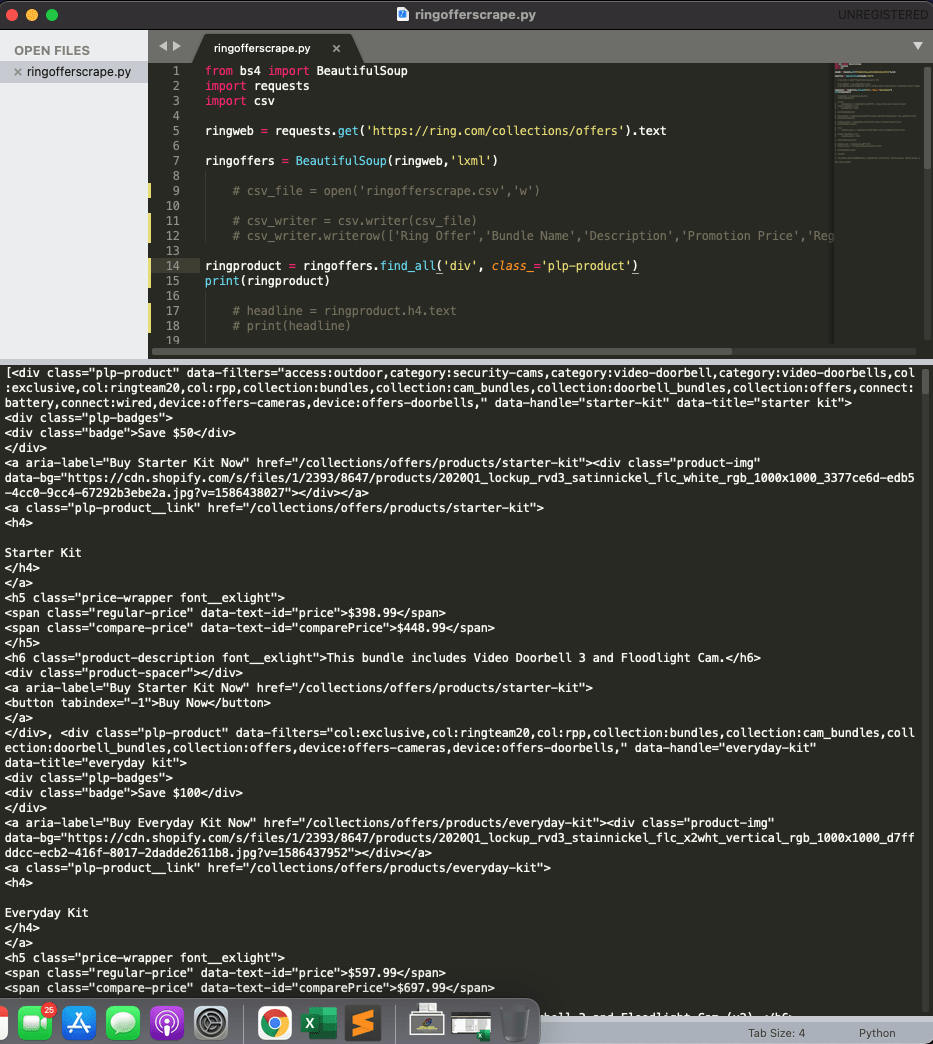
Especificar los datos para analizar y raspar
Ahora comenzamos a analizar los datos de la sección de destino y los datos específicos que queremos raspar, como mencionamos anteriormente en este artículo.<. /p>
En primer lugar, es el titular del producto
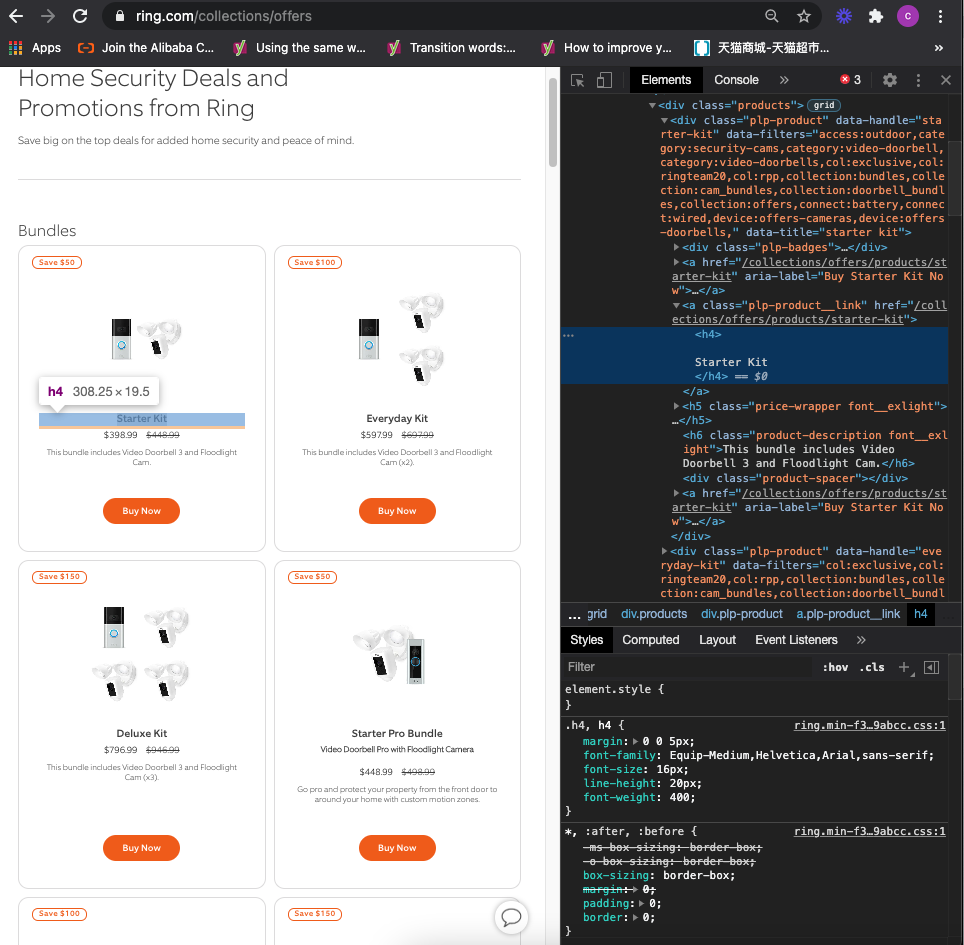
Podemos inspeccionar y ver desde las herramientas de desarrollador, Ring ofrece la página H4 solo representa el titular de los productos del paquete, por lo que podemos escribir directamente una línea de código:
headline = ringproduct.h4.text
print(headline)
En Python, dividimos una ruta usando un punto, excepto una ruta dentro de un método. A medida que raspamos los datos de la cadena, para que podamos usar el texto después de H4.
Entonces, su subterránea y descripción
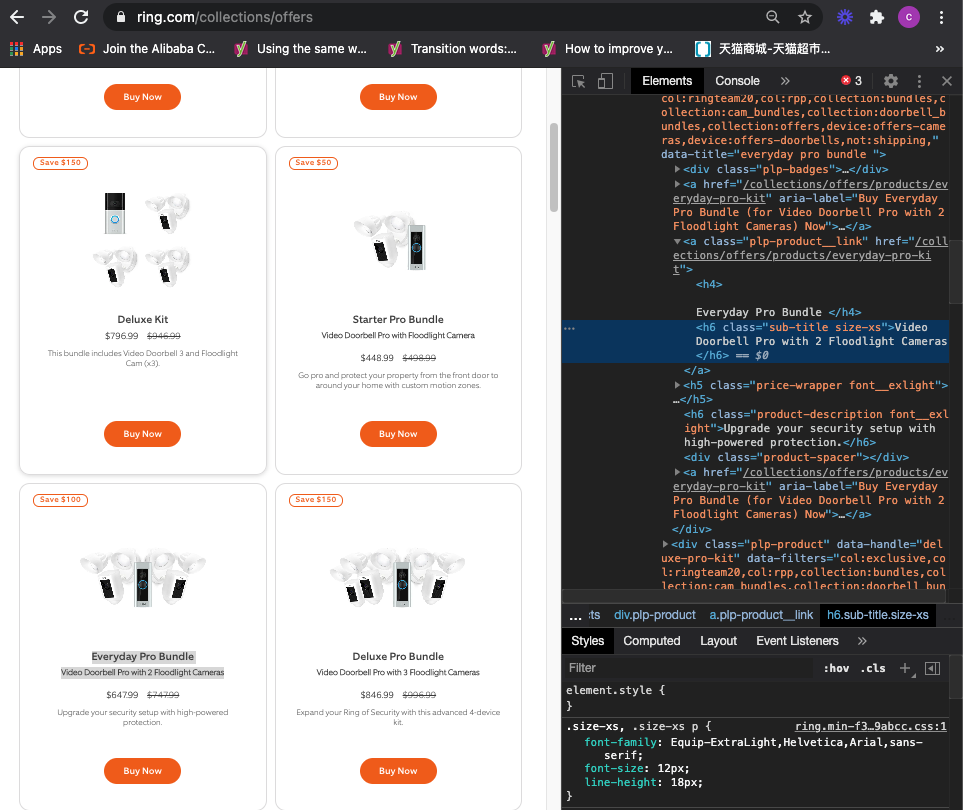
We can see there are two places that are using h6 (subheadline and description). So different from the headline, we need to use find() method and locate a specific h6 data
subheadline = ringproduct.find('h6', class_='sub-title size-xs').text
print(subheadline)
description = ringproduct.find('h6',class_='product-description font__exlight').text
print(description)
Descubriría que no todos los paquetes de productos tienen subterráneos. En Python, necesitamos pasar los datos faltantes para evitar errores en la ejecución del archivo de script. Lo hablaré en un momento.
Entonces, es el precio regular y el precio de promoción
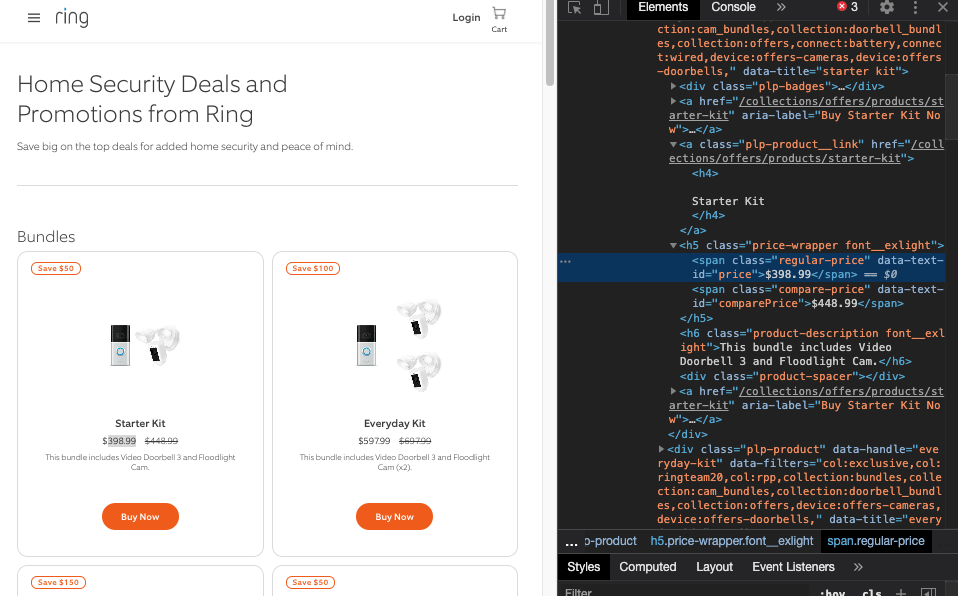
promote_price = ringproduct.find('span',class_='regular-price').text
print(promote_price)
regular_price = ringproduct.find('span',class_='compare-price').text
print(regular_price)
Por último, pero no menos importante, es la URL de aterrizaje del producto
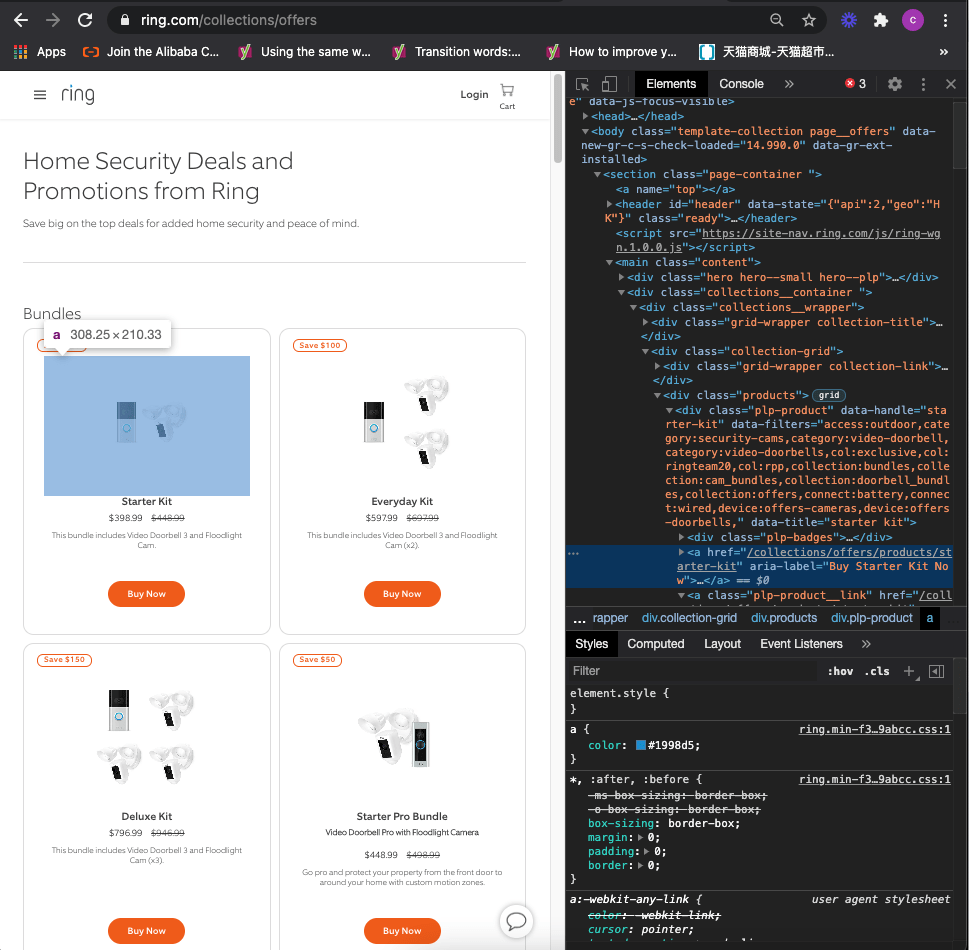
Líneas de código:
product_url = ringproduct.a['href']
product_link = f'https://ring.com{product_url}'
print(product_link)
Basically, there’s only one unique URL showing in the source code of each product bundle. For example, the product starter kit landing path is collections/offers/products/starter-kit. So we could ignore which value we aim to scrape and directly leverage [ ], to scrape href value in a section: product_url = ringproduct.a['href']
Sin embargo, si raspamos estas rutas de datos en un archivo, no se pueden abrir y acceder en la página. Entonces, para mostrar la URL completa, podemos crear una variable product_link y aprovechar la función de formato usando F ‘’ e insertar productos_url en {}.
product_link = f'https://ring.com{product_url}’
Si intentamos imprimir esto, podemos tener un resultado que demuestre que está funcionando.
Cree un bucle para raspar todos los datos especificados por la sección
Estas líneas de código están funcionando para que podamos extenderlo para raspar todos los datos a granel. Para esto, necesitamos usar para … en y finales métodos:
for ringproduct in ringoffers.find_all('div', class_='plp-product'):
Como este código está a nivel de los padres,, necesitamos agregar un colon al final de esta línea de có. digo y líneas para niños con sangría.
Si intentamos imprimir esto, podemos ver el resultado en la lista a continuación, que incluye toda la información del paquete de productos.
Pasar los datos faltantes en algunas secciones
You might be aware that not all product bundles have subheadline and promotion price, so if you try to run subheadline and promotion price lines of code if you come across this response from Python: object has no attribute ‘text’, and it would stop the scraping process.
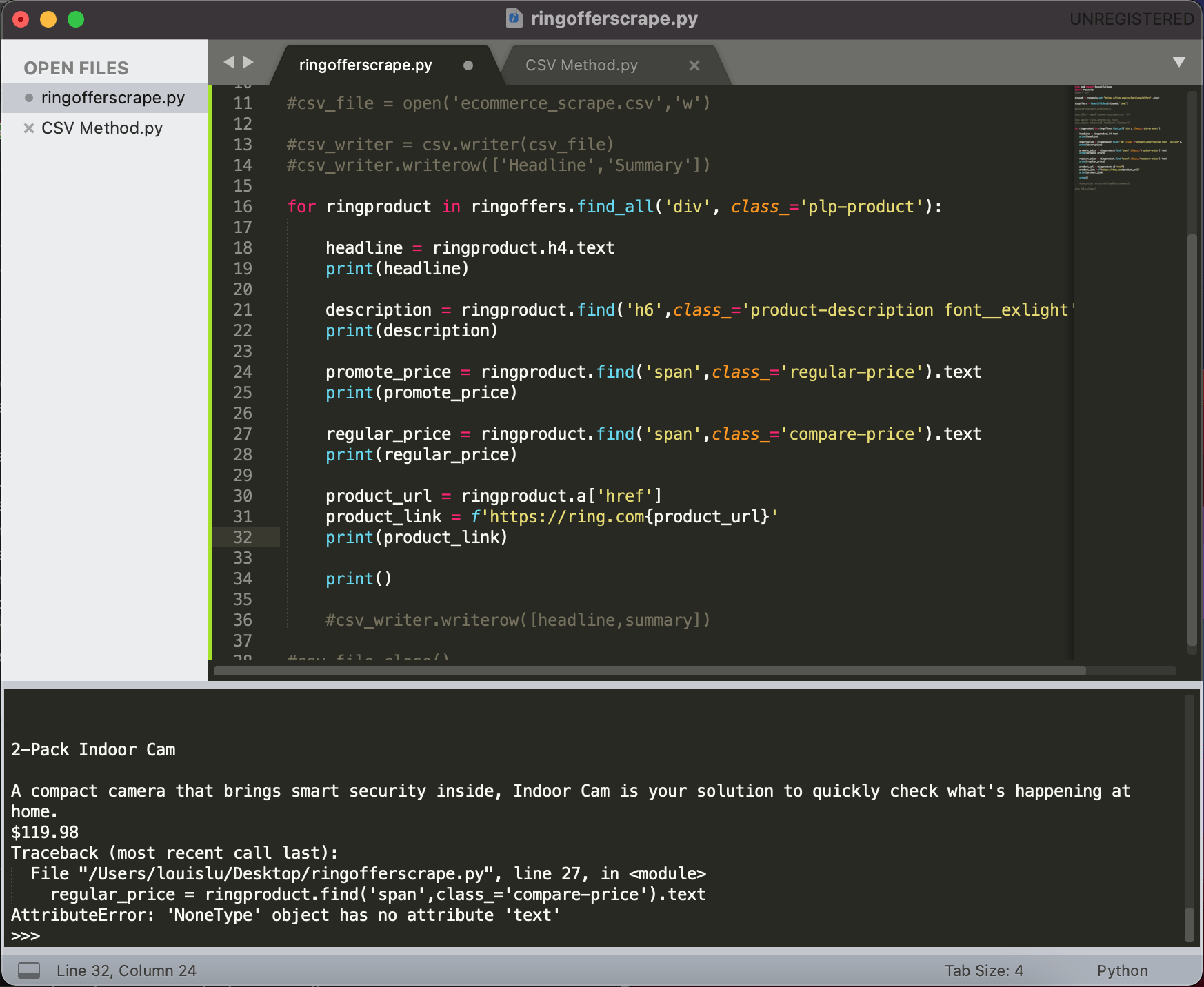
Este es el reflejo del mundo de la codificación porque no toda la información está en orden y estructurada. Por lo tanto, debemos usar Try/Excepto para pasar esto cuando nos encontramos.
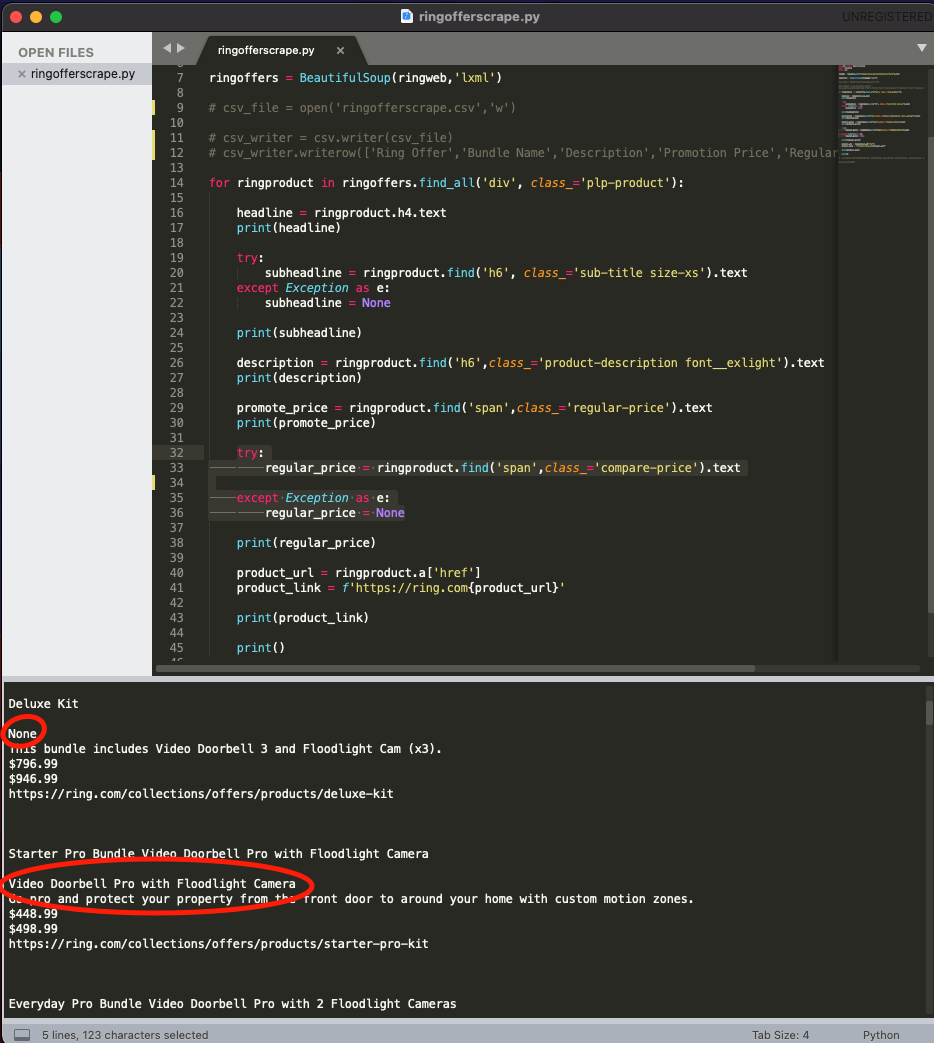
Subtítulo:
try:
subheadline = ringproduct.find('h6', class_='sub-title size-xs').text
except Exception as e:
subheadline = None
Precio de promoción:
try:
regular_price = ringproduct.find('span',class_='compare-price').text
except Exception as e:
regular_price = None
Para el valor variable en excepción de la excepción como E, puede establecerlo, ya que siente que es fácil de entender, como ninguno, 0, «na», etc.
No establecí ninguno, para que puedas ver el resultado de la respuesta
Guarde los datos en un archivo CSV
Ahora el script de Python está listo, y es hora de guardar los datos raspados en un lugar, que puede ser un archivo local o un servidor en línea.
Voy a entrar en detalles sobre el archivo CSV porque hablé sobre esta lección anteriormente. Si está interesado, consulte el otro artículo
Capítulo 3: Utilice el módulo CSV para escribir, analizar, leer archivos CSV para administrar datos raspados
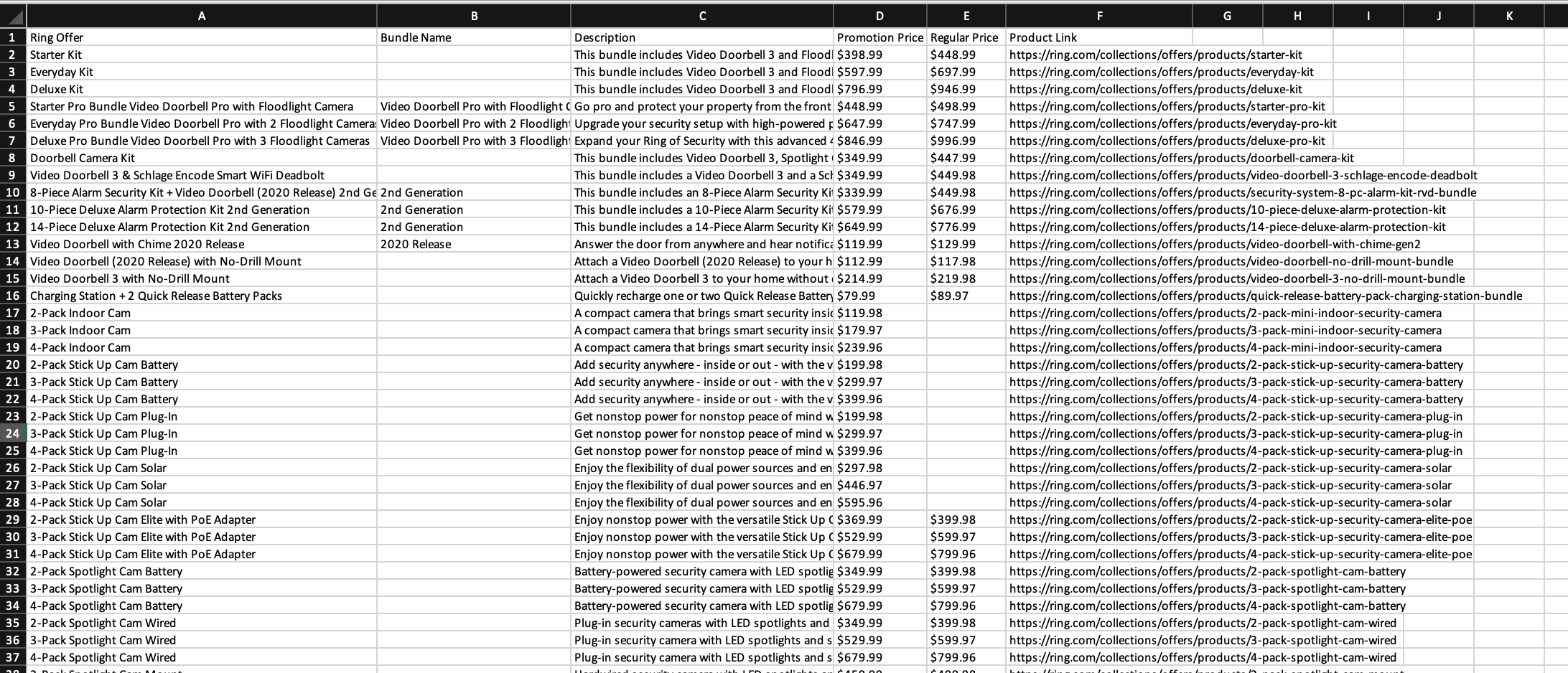
Una vez realizado los códigos, un archivo CSV como el siguiente aparecería y almacenaría todos los datos especificados que nuestro objetivo es raspar.
Script de Python completo de Bot del sitio web
If you would like to have the full version of the Python Script of Website Bot, please subscribe to our newsletter by adding the message Chapter 4. We would send you the script immediately to your mailbox.
Contáctenos
Tan fácil, ¿verdad? Espero que disfrute leyendo el Capítulo 4: Cree un bot del sitio web para raspar datos específicos del sitio web utilizando BeautifulSoup. Si lo hizo, por favor nos apoye haciendo una de las cosas enumeradas a continuación, porque siempre ayuda a nuestro canal.
- Support and donate to our channel through PayPal (paypal.me/Easy2digital)
- S. ubscribe to my channel and turn on the notification bell Easy2Digital Youtube channel.
- Follow and like my page Easy2Digital Facebook page
- Comparta el artículo en su red social con el hashtag #Easy2Digital
- Buy products with Easy2Digital 10% OFF Discount code (Easy2DigitalNewBuyers2021)
- Usted se registra en nuestro boletín semanal para recibir los últimos artículos, videos y códigos de descuento de Easy2Digital.
- Subscribe to our monthly membership through Patreon to enjoy exclusive benefits (www.patreon.com/louisludigital)
Además de raspar datos web HTML y XML, si está interesado en aprender a obtener algunos datos de plataforma a los que solo se puede acceder a través de API, consulte este artículo y comenzaríamos con el canal de YouTube.
Capítulo 5 – Construya un bot de YouTube para raspar videos de tendencia usando YouTube y API Easy2Digital
Tabla de contenido:

