L’algorithme de forêt aléatoire a été appliqué dans un certain nombre d’industries, ce qui leur permet de prendre de meilleures décisions commerciales. Certains cas d’utilisation comprennent une analyse élevée des risques de crédit et une recommandation de produits à des fins de vente croisée.
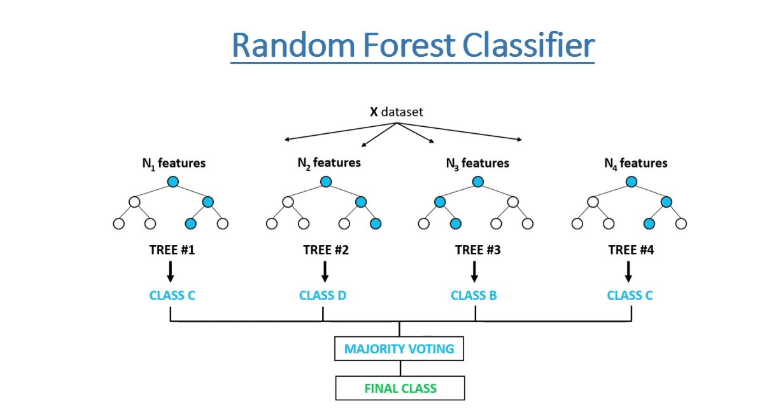
Dans cette pièce, je vous guiderais brièvement à travers plusieurs méthodes de génération d’importance des fonctionnalités en utilisant un ensemble de données de validateur de qualité du vin rouge classique. À la fin de ce chapitre, vous pouvez avoir un concept de base pour utiliser une forêt aléatoire appliquée à vos projets et comparer le résultat entre les différentes méthodes.
Table des matières: générer l’importance de la caractéristique de l’objet en utilisant Scikit Learn et Random Forest in Machine Learning
Red Wine Dataset and Data Training Split
Pour tout modèle d’apprentissage automatique, obtenir un ensemble de données approprié ou prétraiter les données sont essentielles. Kaggle est l’une des plates-formes les plus populaires pour que vous puissiez rechercher un ensemble de données approprié. Voici le lien pour le projet de qualité du vin rouge.
https://www.kag. gle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
première chose, le traitement des données à l’aide de pandas et sklearn train_test_split est la première étape.
url = " Winequality-red.csv "
wine_data = pd . read_csv ( url , sep = " ; ")
x = wine_data . drop ( 'Quality' , axe = 1 )
y = wine_data [ 'Quality' ]
x_train , x_test , y_train , y_test = Train_test_split ( x , y , test_size = 0,5 , random_state = 50 )
Importance de fonction intégrée avec Scikit-Learn
Scikit-learn fournit une méthode d’importance de fonctionnalité intégrée pour les modèles forestiers aléatoires. Selon la documentation, cette méthode est basée sur la diminution de l’impureté de nœud.
![blog detail]()
Dans une forêt aléatoire, les questions sont comme les fonctionnalités du modèle. Certaines questions vous aident à éliminer plus de possibilités que d’autres. L’hypothèse est que les fonctionnalités qui vous aident à éliminer rapidement plus de possibilités sont plus importantes car elles vous aident à vous rapprocher de la bonne réponse plus rapidement. Il est très simple d’obtenir ces importations de fonctionnalités avec Scikit-Learn:
rf = randomforestRegressor ( n_estimators = 100 , random_state = 50 )
rf . fit ( x_train , y_train )
inbuilt_importances = pd . série ( rf . feature_importances _ , index = x_train . Colonnes)
inbuilt_importances . sort_values ( ascendant = true , inplace = true )
inbuilt_importances . tracé . barh ( Color = 'noir' )
Méthode Scikit-Learn intégrée avec une fonctionnalité aléatoire
Le moyen le plus simple de faire avancer cette méthode est d’ajouter une fonctionnalité aléatoire à l’ensemble de données et de voir si le résultat peut être dévié plus que le 1er sans aléatoire.
Si une fonctionnalité réelle a une importance plus faible que la fonctionnalité aléatoire, elle pourrait indiquer que son importance est juste due au hasard.
def randométhod ():
x_train_random = x_train . Copy ()
x_train_random [" random "] = np . aléatoire . randomstate ( 42 ). randn ( x_train . Forme [ 0 ])
rf_random = randomforestRegressor ( n_estimators = 100 , random_state = 42 )
rf_random . fit ( x_train_random , y_train )
importations_random = pd . série ( rf_random . FEAUTHE_IMPORMES _ , index = X_train_random . Colonnes)
importations_random . sort_values ( ASCENSEMP = true , inplace = true )
importations_random . tracé . Barh ( Color = 'bleu' )
plt . xlabel (" Importance ")
plt . ylabel (" Fonction ")
plt . title (" Importance de la fonction - Scikit Learn INTÉRIEUR avec aléatoire ")
plt . show ()
return
la fonction de permutation importance
La caractéristique de la permutation est une autre technique pour estimer l’importance de chaque caractéristique dans un modèle forestier aléatoire en mesurant le changement des performances du modèle lorsque les valeurs de la fonctionnalité sont mélangées au hasard.
L’un des avantages de cette méthode est qu’il peut être utilisé avec n’importe quel modèle, pas seulement des forêts aléatoires, ce qui rend les résultats entre les modèles plus comparables.
la caractéristique de la forêt aléatoire Importance avec Snap
La forme est une méthode pour interpréter la sortie des modèles d’apprentissage automatique en fonction de la théorie du jeu.
Il fournit une mesure unifiée de l’importance des caractéristiques qui, comme l’importance de la permutation, peut être appliquée à n’impo. rte quel modèle.
L’inconvénient principal est qu’il peut être coûteux en calcul, en particulier pour les grands ensembles de données ou les modèles complexes.
Random Forest Path Feature Importance
![blog detail]()
Une autre façon de comprendre comment chaque caractéristique contribue aux prédictions forestières aléatoires est de regarder les chemins d’arbre de décision que chaque instance prend.
Il calcule la différence entre la valeur de prédiction au niveau du nœud feuille et les valeurs de prédiction aux nœuds qui le précèdent pour obtenir la contribution estimée de chaque fonctionnalité.
Full Python script du générateur d’importance de caractéristique
Si vous êtes intéressé par le chapitre 76 – Générez l’importance de la caractéristique de l’objet à l’aide de Scikit Learn et Random Forest, s’il vous plaît Abonnez-vous à notre newsletter en ajoutant le message ‘Chapitre 75 + API de notion’ . Nous vous enverrions immédiatement le script dans votre boîte aux lettres.
J’espère que vous apprécierez la lecture du chapitre 76 – Générez l’importance de la caractéristique de l’objet en utilisant Scikit Learn et Random Forest. Si vous l’avez fait, veuillez nous soutenir en faisant l’une des choses énumérées ci-dessous, car cela aide toujours notre chaîne.
- Soutenez et faites un don à notre chaîne via PayPal (paypal.me/Easy2digital)
- Abonnez-vous à ma chaîne et activez la cloche de notification Easy2Digital chaîne Youtube.
- Suivez et aimez ma page Easy2Digital page Facebook Easy2Digital
- Partagez l’article sur votre réseau social avec le hashtag #easy2digital
- Abonnez-vous à notre bulletin hebdomadaire pour recevoir les derniers articles, vidéos et codes de réduction d’Easy2Digital
- Abonnez-vous à notre adhésion mensuelle via Patreon pour profiter d’avantages exclusifs (www.patreon.com/louisludigital)
