

랜덤 포레스트 알고리즘은 여러 산업에 걸쳐 적용되어 더 나은 비즈니스 결정을 내릴 수 있게 되었습니다. 일부 사용 사례에는 높은 신용 위험 분석 및 교차 판매 목적을 위한 상품 추천이 포함됩니다.
이 글에서는 전통적인 레드 와인 품질 검사기 데이터세트를 사용하여 기능 중요도를 생성하는 여러 가지 방법을 간략하게 안내하겠습니다. 이 장을 마치면 프로젝트에 Random Forest를 적용하고 다양한 방법으로 결과를 비교하는 기본 개념을 갖게 됩니다.
목차: 기계 학습에서 Scikit learn 및 Random Forest를 사용하여 객체 기능 중요도 생성
- 레드 와인 데이터 세트 및 데이터 교육 분할
- Scikit-learn의 내장 기능 중요성
- 무작위 기능을 갖춘 내장형 Scikit-learn 방법
- 순열 기능의 중요성
- SNAP의 랜덤 포레스트 기능 중요성
- 랜덤 포레스트 경로 기능 중요성
- 기능 중요도 생성기의 전체 Python 스크립트
- 데이터 과학 및 기계 학습 Courseresa 추천 과정
레드 와인 데이터 세트 및 데이터 교육 분할
모든 기계 학습 모델의 경우 적절한 데이터 세트를 얻거나 데이터를 전처리하는 것이 중요합니다. Kaggle은 적절한 데이터 세트를 찾는 데 가장 인기 있는 플랫폼 중 하나입니다. 레드 와인 품질 프로젝트에 대한 링크는 다음과 같습니다.
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
가장 먼저, Pandas와 Sklearn train_test_split을 사용하여 데이터를 처리하는 것이 첫 번째 단계입니다.
url = "winequality-red.csv"
wine_data = pd . read_csv ( url , sep = ";" )
x = wine_data . drop ( 'quality' , axis = 1 )
y = wine_data [ 'quality' ]
x_train , x_test , y_train , y_test = train_test_split ( x , y , test_size = 0.5 , random_state = 50 )
Scikit-learn의 내장 기능 중요성
Scikit-learn은 Random Forest 모델에 대한 내장된 기능 중요도 방법을 제공합니다. 문서에 따르면 이 방법은 노드 불순물의 감소를 기반으로 합니다.
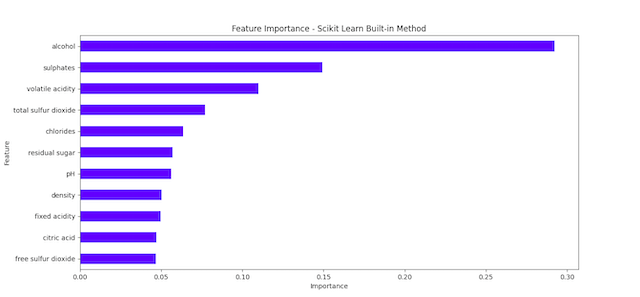
Random Forest에서 질문은 모델의 기능과 같습니다. 일부 질문은 다른 질문보다 더 많은 가능성을 제거하는 데 도움이 됩니다. 더 많은 가능성을 빠르게 제거하는 데 도움이 되는 기능이 정답에 더 빠르게 가까워지는 데 도움이 되기 때문에 더 중요하다고 가정합니다. Scikit-learn을 사용하면 이러한 기능 중요성을 얻는 것이 매우 간단합니다.
rf = RandomForestRegressor ( n_estimators = 100 , random_state = 50 )
rf . fit ( x_train , y_train )
inbuilt_importances = pd . Series ( rf . feature_importances_ , index = x_train .columns)
inbuilt_importances . sort_values ( ascending = True , inplace = True )
inbuilt_importances . plot . barh ( color = 'black' )
무작위 기능을 갖춘 내장된 Scikit-learn 방법
이 방법을 발전시키는 가장 간단한 방법은 데이터 세트에 무작위 특성을 추가하고 결과가 무작위 없이 첫 번째 것보다 더 많이 벗어날 수 있는지 확인하는 것입니다.
실제 특성이 무작위 특성보다 중요도가 낮다면 그 중요성이 단지 우연에 의한 것임을 나타낼 수 있습니다.
def randomMethod ():
X_train_random = x_train .copy()
X_train_random [ "RANDOM" ] = np . random . RandomState ( 42 ). randn ( x_train .shape[ 0 ])
rf_random = RandomForestRegressor ( n_estimators = 100 , random_state = 42 )
rf_random . fit ( X_train_random , y_train )
importances_random = pd . Series ( rf_random . feature_importances_ , index = X_train_random .columns)
importances_random . sort_values ( ascending = True , inplace = True )
importances_random . plot . barh ( color = 'blue' )
plt . xlabel ( "Importance" )
plt . ylabel ( "Feature" )
plt . title ( "Feature Importance - Scikit Learn Built-in with random" )
plt . show ()
return
순열 기능의 중요성
순열 특성 중요도는 특성 값이 무작위로 섞일 때 모델 성능의 변화를 측정하여 Random Forest 모델에서 각 특성의 중요도를 추정하는 또 다른 기술입니다.
이 방법의 장점 중 하나는 Random Forests뿐만 아니라 모든 모델에 사용할 수 있어 모델 간 결과를 더 비교할 수 있다는 것입니다.
SNAP의 랜덤 포레스트 기능 중요성
SHAP은 게임 이론을 기반으로 머신러닝 모델의 출력을 해석하는 방법입니다.
순열 중요도와 마찬가지로 모든 모델에 적용할 수 있는 기능 중요도에 대한 통합된 측정값을 제공합니다.
가장 큰 단점은 특히 대규모 데이터 세트나 복잡한 모델의 경우 계산 비용이 많이 들 수 있다는 것입니다.
랜덤 포레스트 경로 기능 중요성
각 기능이 Random Forest 예측에 어떻게 기여하는지 이해하는 또 다른 방법은 각 인스턴스가 취하는 의사결정 트리 경로를 살펴보는 것입니다.
리프 노드의 예측 값과 그 이전 노드의 예측 값 간의 차이를 계산하여 각 특성의 예상 기여도를 얻습니다.
기능 중요도 생성기의 전체 Python 스크립트
76장 – Scikit learn 및 Random Forest를 사용하여 객체 기능 중요도 생성에 관심이 있다면, 'Chapter 75 + notion api' 메시지를 추가하여 뉴스레터를 구독 하세요. . 우리는 즉시 귀하의 사서함으로 스크립트를 보내드립니다.
76장 – Scikit learn 및 Random Forest를 사용하여 객체 기능 중요도 생성을 재미있게 읽으시기 바랍니다. 그렇게 했다면 아래 나열된 일 중 하나를 수행하여 우리를 지원해 주세요. 이는 항상 우리 채널에 도움이 되기 때문입니다.
- PayPal( paypal.me/Easy2digital )을 통해 채널을 지원하고 기부하세요.
- 내 채널을 구독하고 Easy2Digital Youtube 채널 알림 벨을 켜십시오.
- 내 페이지 Easy2Digital Facebook 페이지를 팔로우하고 좋아요를 누르세요.
- 해시태그 #easy2digital을 사용하여 소셜 네트워크에 기사를 공유하세요.
- Easy2Digital 최신 기사, 비디오 및 할인 코드를 받으려면 주간 뉴스레터에 가입하세요.
- Patreon을 통해 월간 멤버십을 구독하여 독점적인 혜택을 누리세요( www.patreon.com/louisludigital )