

Алгоритм случайного леса применяется во многих отраслях, что позволяет им принимать более эффективные бизнес-решения. Некоторые варианты использования включают анализ высокого кредитного риска и рекомендации по продуктам для целей перекрестных продаж.
В этой статье я кратко расскажу вам о нескольких методах определения важности признаков с использованием классического набора данных валидатора качества красного вина. К концу этой главы вы сможете получить базовую концепцию использования случайного леса в своих проектах и сравнить результаты различных методов.
Оглавление: создание важности функции объекта с использованием обучения Scikit и случайного леса в машинном обучении
- Набор данных о красном вине и разделение обучения данных
- Встроенная важность функций с помощью Scikit-learn
- Встроенный метод обучения Scikit со случайной функцией
- Важность функции перестановки
- Важность случайного объекта леса с помощью SNAP
- Важность функции случайного лесного пути
- Полные Python-скрипты генератора важности функций
- Рекомендации по курсу «Наука о данных и машинное обучение»
Набор данных о красном вине и разделение обучения данных
Для любой модели машинного обучения критически важно получить правильный набор данных или выполнить предварительную обработку данных. Kaggle — одна из самых популярных платформ для поиска подходящего набора данных. Вот ссылка на проект по качеству красного вина.
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
Прежде всего, первым шагом является обработка данных с помощью Pandas и Sklearn train_test_split.
url = "winequality-red.csv"
wine_data = pd . read_csv ( url , sep = ";" )
x = wine_data . drop ( 'quality' , axis = 1 )
y = wine_data [ 'quality' ]
x_train , x_test , y_train , y_test = train_test_split ( x , y , test_size = 0.5 , random_state = 50 )
Встроенная важность функций с помощью Scikit-learn
Scikit-learn предоставляет встроенный метод важности функций для моделей случайного леса. Согласно документации, этот метод основан на уменьшении засоренности узла.

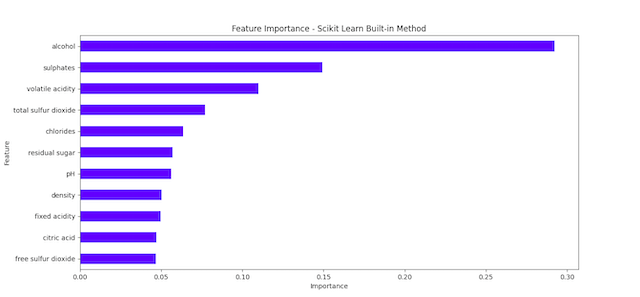
В случайном лесу вопросы подобны функциям модели. Некоторые вопросы помогут вам исключить больше возможностей, чем другие. Предполагается, что функции, которые помогают вам быстро исключить больше возможностей, более важны, потому что они помогают вам быстрее приблизиться к правильному ответу. Очень просто определить важность этих функций с помощью Scikit-learn:
rf = RandomForestRegressor ( n_estimators = 100 , random_state = 50 )
rf . fit ( x_train , y_train )
inbuilt_importances = pd . Series ( rf . feature_importances_ , index = x_train .columns)
inbuilt_importances . sort_values ( ascending = True , inplace = True )
inbuilt_importances . plot . barh ( color = 'black' )
Встроенный метод обучения Scikit со случайной функцией
Самый простой способ усовершенствовать этот метод — добавить случайный признак в набор данных и посмотреть, может ли результат отклоняться больше, чем первый без случайного.
Если реальный признак имеет меньшую важность, чем случайный признак, это может указывать на то, что его важность обусловлена просто случайностью.
def randomMethod ():
X_train_random = x_train .copy()
X_train_random [ "RANDOM" ] = np . random . RandomState ( 42 ). randn ( x_train .shape[ 0 ])
rf_random = RandomForestRegressor ( n_estimators = 100 , random_state = 42 )
rf_random . fit ( X_train_random , y_train )
importances_random = pd . Series ( rf_random . feature_importances_ , index = X_train_random .columns)
importances_random . sort_values ( ascending = True , inplace = True )
importances_random . plot . barh ( color = 'blue' )
plt . xlabel ( "Importance" )
plt . ylabel ( "Feature" )
plt . title ( "Feature Importance - Scikit Learn Built-in with random" )
plt . show ()
return
Важность функции перестановки
Важность функции перестановки — это еще один метод оценки важности каждой функции в модели случайного леса путем измерения изменения производительности модели, когда значения функции случайным образом перемешиваются.
Одним из преимуществ этого метода является то, что его можно использовать с любой моделью, а не только со случайными лесами, что делает результаты между моделями более сопоставимыми.
Важность случайного объекта леса с помощью SNAP
SHAP — это метод интерпретации результатов моделей машинного обучения, основанный на теории игр.
Он обеспечивает единую меру важности функции, которую, как и важность перестановки, можно применять к любой модели.
Основным недостатком этого подхода является то, что он может быть дорогостоящим в вычислительном отношении, особенно для больших наборов данных или сложных моделей.
Важность функции случайного лесного пути
Другой способ понять, как каждая функция влияет на прогнозы случайного леса, — это посмотреть на пути дерева решений, которые использует каждый экземпляр.
Он вычисляет разницу между значением прогноза на конечном узле и значениями прогноза в узлах, которые ему предшествуют, чтобы получить предполагаемый вклад каждого признака.
Полный Python- скрипт генератора важности функций
Если вас интересует глава 76 «Создание важности функции объекта с помощью обучения Scikit и случайного леса», подпишитесь на нашу рассылку , добавив сообщение «Глава 75 + понятие API». . Мы немедленно отправим вам сценарий на ваш почтовый ящик.
Надеюсь, вам понравится читать главу 76 «Создание важности функций объекта с помощью обучения Scikit и случайного леса». Если да, поддержите нас, выполнив одно из действий, перечисленных ниже, потому что это всегда помогает нашему каналу.
- Поддержите наш канал и сделайте пожертвование через PayPal ( paypal.me/Easy2digital ).
- Подпишитесь на мой канал и включите колокольчик Easy2Digital Youtube-канал .
- Подпишитесь на мою страницу и поставьте ей лайк. Страница Easy2Digital в Facebook.
- Поделитесь статьей в своей социальной сети с хэштегом #easy2digital.
- Вы подписываетесь на нашу еженедельную рассылку, чтобы получать последние статьи, видео и коды скидок Easy2Digital.
- Подпишитесь на наше ежемесячное членство через Patreon, чтобы пользоваться эксклюзивными преимуществами ( www.patreon.com/louisludigital ).