随机森林算法已应用于许多行业,使他们能够做出更好的业务决策。一些用例包括高信用风险分析和用于交叉销售目的的产品推荐。
在这篇文章中,我将简要介绍几种使用经典红酒质量验证器数据集生成特征重要性的方法。在本章结束时,您可以掌握将随机森林应用于您的项目的基本概念,并比较不同方法的结果。
目录:在机器学习中使用 Scikit learn 和随机森林生成对象特征重要性
- 红酒数据集和数据训练拆分
- Scikit-learn 的内置功能重要性
- 具有随机特征的内置 Scikit-learn 方法
- 排列特征重要性
- SNAP 的随机森林特征重要性
- 随机森林路径特征重要性
- 特征重要性生成器的完整 Python 脚本
- 数据科学与机器学习 Coursera 课程推荐
红酒数据集和数据训练拆分
对于任何机器学习模型,获取正确的数据集或预处理数据至关重要。 Kaggle 是最流行的查找合适数据集的平台之一。这是红酒质量项目的链接。
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
首先,使用 Pandas 和 Sklearn train_test_split 处理数据是第一步。
url = "winequality-red.csv"wine_data = pd . read_csv ( url , sep = ";" )x = wine_data . drop ( 'quality' , axis = 1 )y = wine_data [ 'quality' ]x_train , x_test , y_train , y_test = train_test_split ( x , y , test_size = 0.5 , random_state = 50 )Scikit-learn 的内置功能重要性
Scikit-learn 为随机森林模型提供了内置的特征重要性方法。根据文档,该方法是基于节点杂质的减少。
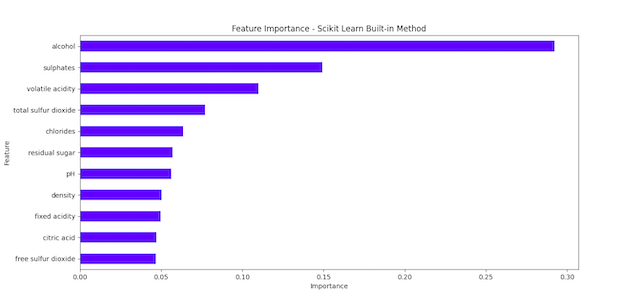
在随机森林中,问题就像模型中的特征。有些问题可以帮助您比其他问题消除更多的可能性。我们的假设是,帮助您快速消除更多可能性的功能更为重要,因为它们可以帮助您更快地接近正确答案。使用 Scikit-learn 获取这些特征重要性非常简单:
rf = RandomForestRegressor ( n_estimators = 100 , random_state = 50 )rf . fit ( x_train , y_train )inbuilt_importances = pd . Series ( rf . feature_importances_ , index = x_train .columns)inbuilt_importances . sort_values ( ascending = True , inplace = True )inbuilt_importances . plot . barh ( color = 'black' )具有随机特征的内置 Scikit-learn 方法
推进此方法的最简单方法是向数据集添加随机特征,并查看结果是否可能比没有随机的第一个特征偏差更大。
如果真实特征的重要性低于随机特征,则可能表明其重要性只是偶然的。
def randomMethod (): X_train_random = x_train .copy() X_train_random [ "RANDOM" ] = np . random . RandomState ( 42 ). randn ( x_train .shape[ 0 ]) rf_random = RandomForestRegressor ( n_estimators = 100 , random_state = 42 ) rf_random . fit ( X_train_random , y_train ) importances_random = pd . Series ( rf_random . feature_importances_ , index = X_train_random .columns) importances_random . sort_values ( ascending = True , inplace = True ) importances_random . plot . barh ( color = 'blue' ) plt . xlabel ( "Importance" ) plt . ylabel ( "Feature" ) plt . title ( "Feature Importance - Scikit Learn Built-in with random" ) plt . show () return排列特征重要性
排列特征重要性是另一种技术,通过测量特征值随机打乱时模型性能的变化来估计随机森林模型中每个特征的重要性。
这种方法的优点之一是它可以与任何模型一起使用,而不仅仅是随机森林,这使得模型之间的结果更具可比性。
SNAP 的随机森林特征重要性
SHAP 是一种基于博弈论解释机器学习模型输出的方法。
它提供了特征重要性的统一度量,与排列重要性一样,可以应用于任何模型。
它的主要缺点是计算成本可能很高,尤其是对于大型数据集或复杂模型。
随机森林路径特征重要性
了解每个特征如何对随机森林预测做出贡献的另一种方法是查看每个实例所采用的决策树路径。
它计算叶节点的预测值与其之前节点的预测值之间的差值,以获得每个特征的估计贡献。
特征重要性生成器的完整 Python 脚本
如果您对第 76 章 – 使用 Scikit learn 和随机森林生成对象特征重要性感兴趣,请添加消息“第 75 章 + notion api”来订阅我们的时事通讯。我们会立即将脚本发送到您的邮箱。
我希望您喜欢阅读第 76 章 – 使用 Scikit learn 和随机森林生成对象特征重要性。如果您这样做了,请通过执行下列操作之一来支持我们,因为这总是对我们的频道有所帮助。
- 通过 PayPal ( paypal.me/Easy2digital ) 支持并捐赠我们的频道
- 订阅我的频道并打开通知铃Easy2Digital Youtube 频道。
- 关注并喜欢我的页面Easy2Digital Facebook 页面
- 使用主题标签 #easy2digital 在您的社交网络上分享文章
- 您订阅我们的每周通讯即可接收 Easy2Digital 最新文章、视频和折扣代码
- 通过 Patreon 订阅我们的月度会员即可享受独家优惠 ( www.patreon.com/louisludigital )
