
Pandas的pivot_table()对于开发人员操作数据的功能非常强大,例如数据可视化、数据库存、API开发等。在仪表板开发或数据可视化方面,将特定数据目标从列顺序转置为行顺序是很常见的。因此,在本文中,我将介绍如何使用Pandas hub_table() 和 Python 在一秒钟内批量转置特定数据
使用 Pandas Pivot table() 和 Python 进行数据转置的要素
Python3、Pandas、Google Sheet API(可选)、Microsoft Excel(可选)
目录
数据透视表()
数据透视表并不是一个陌生的术语,因为大多数人都从 Microsoft Excel 中听说过它。在Pandas中,它的功能类似,并且操作数据也非常强大,可以应用于多个领域,例如API数据、AI算法等。
有很多参数可供人们使用并将其应用到应用程序开发中。在本文中,我将以股票公司CAGR计算为例。原始数据如下图所示,其中每个股票代码都有过去5年的年收入,但它以柱形格式对每年的业绩进行排序。
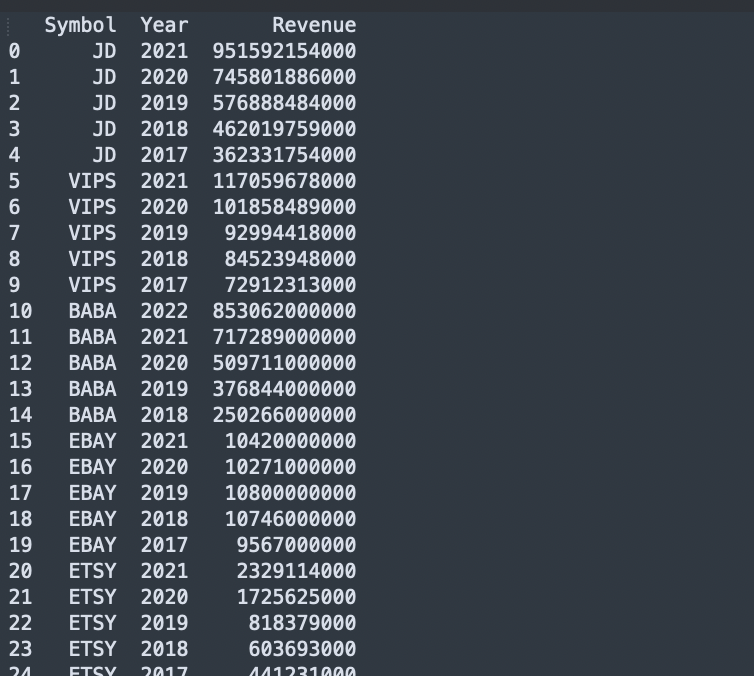
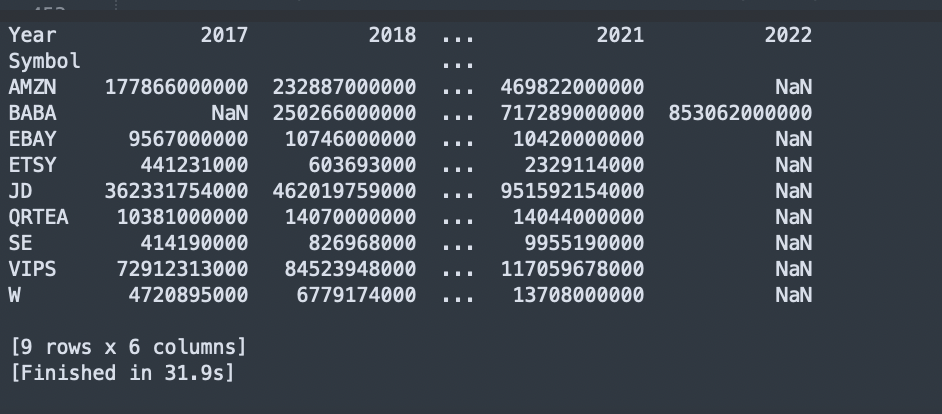
我将使用 4 个参数在一秒钟内将数千条数据行转置为水平视图,如下所示:
- 指数
- 价值
- 列
- 聚合函数
使用 Pandas Pivot_table 操作数据的思维流程
Abc = df.pivot_table(index='Symbol', columns='Year', values='Revenue',aggfunc='first')首先,我们需要告诉系统我们已经选择了一个键或一个索引。该键后面的其余数据将被转置。
索引:列、Grouper、数组或上一个的列表
如果传递一个数组,它必须与数据的长度相同。该列表可以包含任何其他类型(列表除外)。数据透视表索引上分组依据的键。如果传递数组,则其使用方式与列值相同。
根据索引参数的定义,我们应该填写代码,因为唯一键是股票公司代码。人们使用这个唯一的密钥来获取相关数据。
Column:列、Grouper、数组或上一个的列表
列参数与 Index 类似,但列不是唯一的列表或数组。因此,在这里我们将填写年份列表,因为我们喜欢将其从列转置到行。
值:要聚合的列,可选
如果没有 double,这里我们应该填写收入数据集,因为它是计算每个交易品种 CAGR 的基本数据集。
Aggfunc:函数、函数列表、字典、默认numpy.mean
当索引键有多个时,该参数是必须的,容易将系统误认为是有重复键的数据集。不允许有重复的密钥。所以这个参数告诉你请将相同的密钥分配给你在转置过程中遇到的第一个密钥。
aggfunc='first'使用 Pivot_table() 转置股票公司 CAGR 的完整 Python 脚本
如果您对 Pandas Pivot Table() 的完整 Python 脚本感兴趣 – 使用 Pandas & Python 将列序列中的数据批量转置为水平序列,请添加消息“ Pandas数据透视表()转置”来订阅我们的新闻通讯。我们会立即将脚本发送到您的邮箱。
我希望您喜欢阅读 Pandas Pivot Table() – 使用 Pandas 和 Python 将列序列中的数据批量转置为水平数据。如果您这样做了,请通过执行下列操作之一来支持我们,因为这总是对我们的频道有所帮助。
- 通过 PayPal ( paypal.me/Easy2digital ) 支持并捐赠我们的频道
- 订阅我的频道并打开通知铃Easy2Digital Youtube 频道。
- 关注并喜欢我的页面Easy2Digital Facebook 页面
- 使用主题标签 #easy2digital 在您的社交网络上分享文章
- 您订阅我们的每周通讯即可接收 Easy2Digital 最新文章、视频和折扣代码
- 通过 Patreon 订阅我们的月度会员即可享受独家优惠 ( www.patreon.com/louisludigital )
