
Comme mentionné dans le chapitre 3 précédent sur « Comment écrire, analyser et lire des fichiers CSV avec des données récupérées », nous discuterons de la manière de spécifier les données Web à récupérer. C'est parce que c'est l'un des principaux objectifs pour lesquels nous aimons apprendre Python en tant que spécialiste du marketing numérique .
Ainsi, dans ce didacticiel Python destiné aux spécialistes du marketing numérique 4, je vais vous expliquer les concepts et les méthodes de base. C'est avec l'utilisation de Beautifulsoup et Requests que vous devez savoir pour spécifier les données Web et gratter. C'est mieux si vous comprenez comment lire le HTML, le CSS et le javascript dans cette partie. Mais ce n'est pas grave si vous ne l'avez pas encore fait, car le but est de retrouver les données situées à ce moment-là. Et c'est aussi pour apprendre quelques méthodes pour récupérer des données spécifiques à des fins de marketing numérique.
Au cours de la leçon du didacticiel Python, je prendrai Ring.com comme exemple pour écrire des codes et récupérer toutes les dernières offres et tarifs. À la fin du didacticiel Python, vous pouvez identifier l'emplacement des éléments de données attendus sur une page et tout récupérer en quelques minutes.
Table des matières : Créez un robot de site Web pour récupérer des données de site Web spécifiques à l'aide de BeautifulSoup
Identifier la section de données sur une page cible
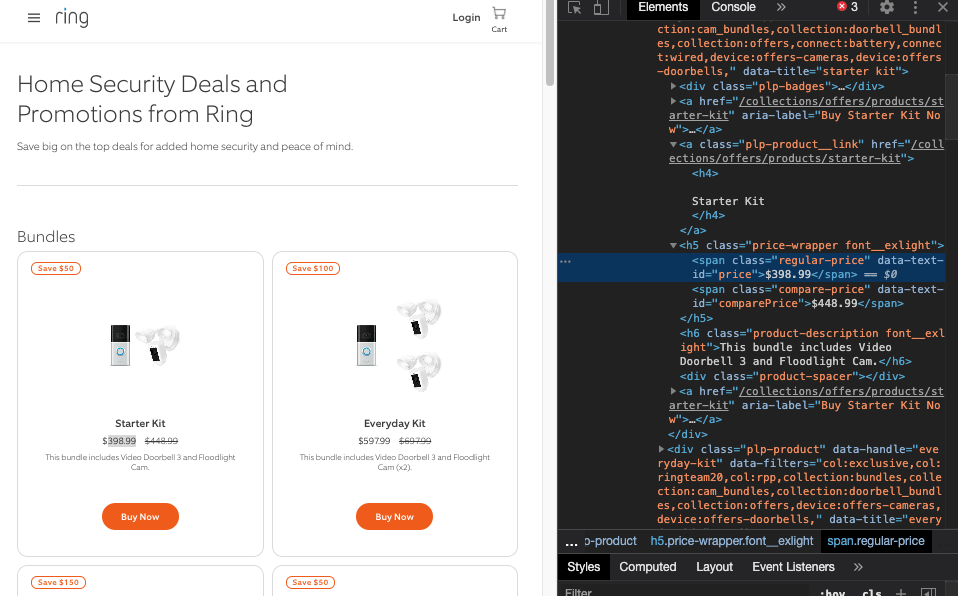
Comme vous pouvez le voir ici, de nombreux offres groupées et offres de produits Ring peuvent être mises à jour de manière irrégulière. Si vous étiez un revendeur Ring ou un concurrent de Ring, vous souhaitez certainement ajuster la stratégie de marketing et de tarification des produits, afin que le taux de conversion ne soit pas affecté si les ventes sont critiques pour votre entreprise.
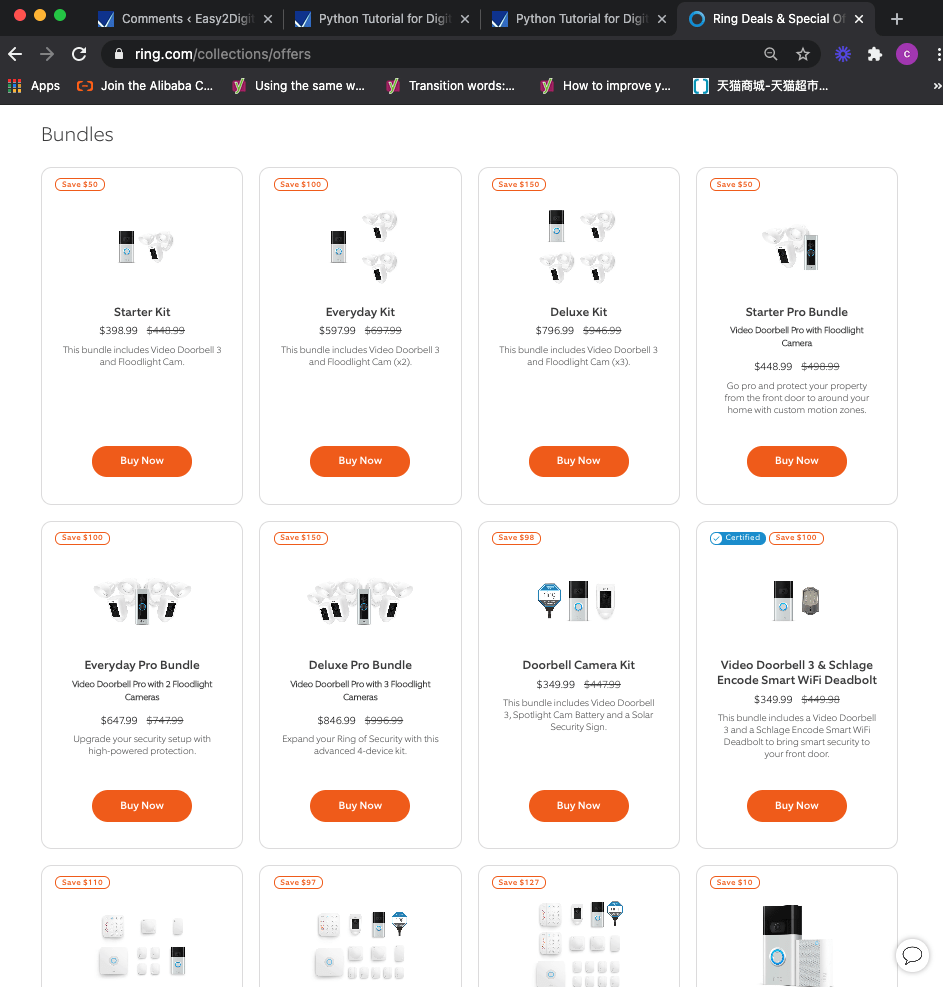
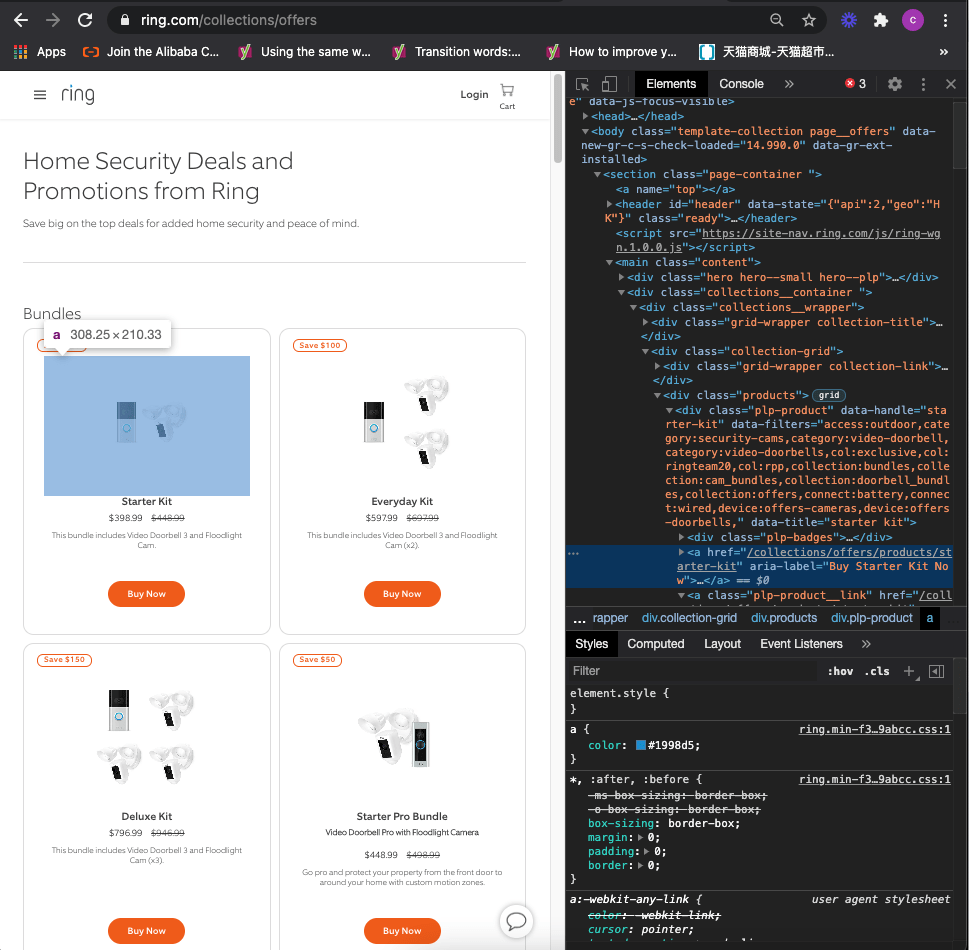
Pour trouver l'emplacement des données, nous devons utiliser un outil de développement de navigateur et inspecter le code source du Web. Je prends Chrome comme exemple, vous pouvez sélectionner un produit et cliquer avec le bouton droit pour sélectionner inspecter.
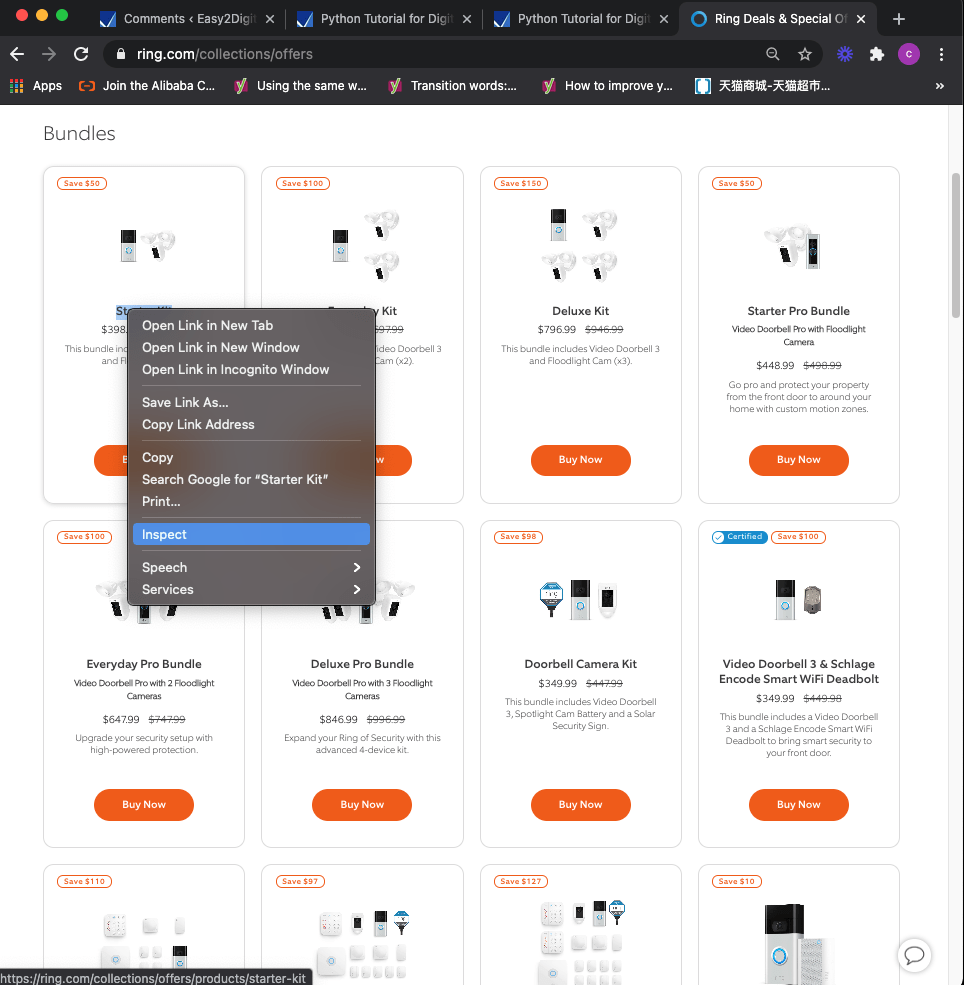
Notre objectif est de récupérer les données des titres, des sous-titres, des prix réguliers, des prix promotionnels, des descriptions et des URL de produits. Sur la base de cet objectif de scraping de données, nous essayons d'examiner le code et de découvrir cette section ou ce que nous appelons la division, qui comprend toutes les données que nous visons à scraper :
<div class=”plp-product”.......</div>
Vous savez que le reste des informations sur les produits commencent tous par la même division :
<div class=”plp-product”.......</div>
Pour voir si cela est correct, nous pouvons commencer à utiliser les méthodes : find() et find_all()
(Remarque : je n'entre pas dans les détails sur la façon d'importer Beautifulsoup, les modules de requêtes. Si vous souhaitez en savoir plus, veuillez consulter les articles précédents :
Chapitre 2 : Web Scraping avec BeautifulSoup, Requests, Python
Web Scraping – Rechercher et trouver toutes les fonctions
Tout d’abord, créons des variables appelées ringweb , ringoffers et ringproduct
ringweb = requests.get('https://ring.com/collections/offers').text
ringoffers = BeautifulSoup(ringweb,'lxml')
La méthode find() est utilisée pour localiser votre action de scraping et obtenir une réponse des données à partir de cet emplacement. Comme le chemin est, <div class=”plp-product”.......</div> pour que nous puissions écrire une ligne de code
ringproduct = ringoffers.find('div', class_='plp-product')
Dans cette ligne de code, nous définons une variable, ringrproduct qui représente les données du chemin cible sous ringoffers . Gardez simplement à l’esprit que dans la méthode Python, nous utilisons généralement des virgules pour diviser le code source HTML et utilisons des guillemets simples pour chaque code source. Concernant la classe, nous devons utiliser class_=, car class= représente l'autre fonction en Python.
Si nous essayons d'imprimer ceci et de commander B, vous pouvez voir que ces lignes de code peuvent déjà récupérer les données de la section. Ça marche.
Comme Ring.com n'a pas qu'un seul ensemble de offres groupées à vendre sur la page de l'offre, nous devons donc utiliser l'autre méthode find_all(). Il nous suffit de remplacer find() par find_all(), vous pouvez voir que toutes les données de la section bundle sont générées.
Spécifiez les données à analyser et à gratter
Nous commençons maintenant à analyser les données de la section cible et les données spécifiques que nous souhaitons récupérer, comme nous l'avons mentionné plus tôt dans cet article.
Tout d'abord, c'est le titre du produit
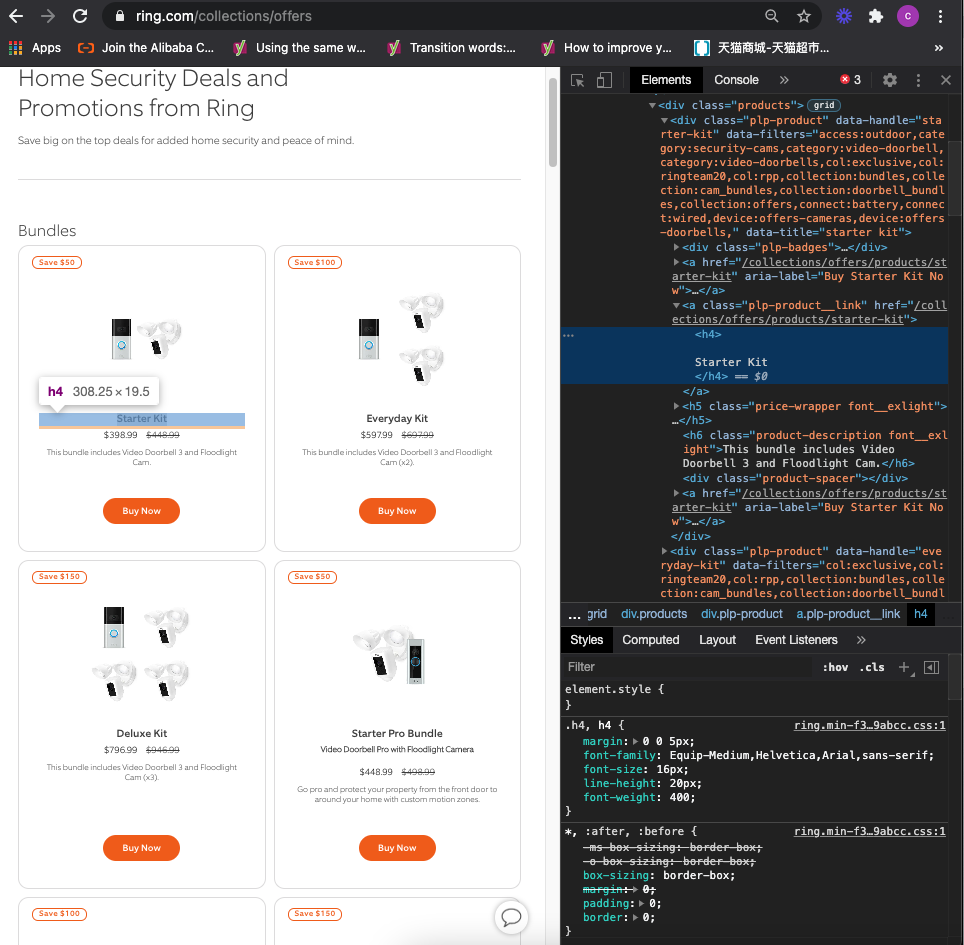
Nous pouvons inspecter et voir à partir des outils de développement, la page h4 des offres Ring ne représente que le titre des produits groupés, nous pouvons donc écrire directement une ligne de code :
headline = ringproduct.h4.text
print(headline)
En Python, nous divisons un chemin en utilisant un point, sauf pour un chemin au sein d'une méthode. Au fur et à mesure que nous récupérons les données de la chaîne, nous pouvons utiliser le texte après h4.
Ensuite, son sous-titre et sa description

Nous pouvons voir qu'il y a deux endroits qui utilisent h6 (sous-titre et description). Si différent du titre, nous devons utiliser la méthode find() et localiser une donnée h6 spécifique
subheadline = ringproduct.find('h6', class_='sub-title size-xs').text
print(subheadline)
description = ringproduct.find('h6',class_='product-description font__exlight').text
print(description)
Vous découvrirez que tous les lots de produits n’ont pas de sous-titres. En Python, nous devons transmettre les données manquantes afin d'éviter les erreurs lors de l'exécution du fichier de script. J'en parlerai dans un instant.
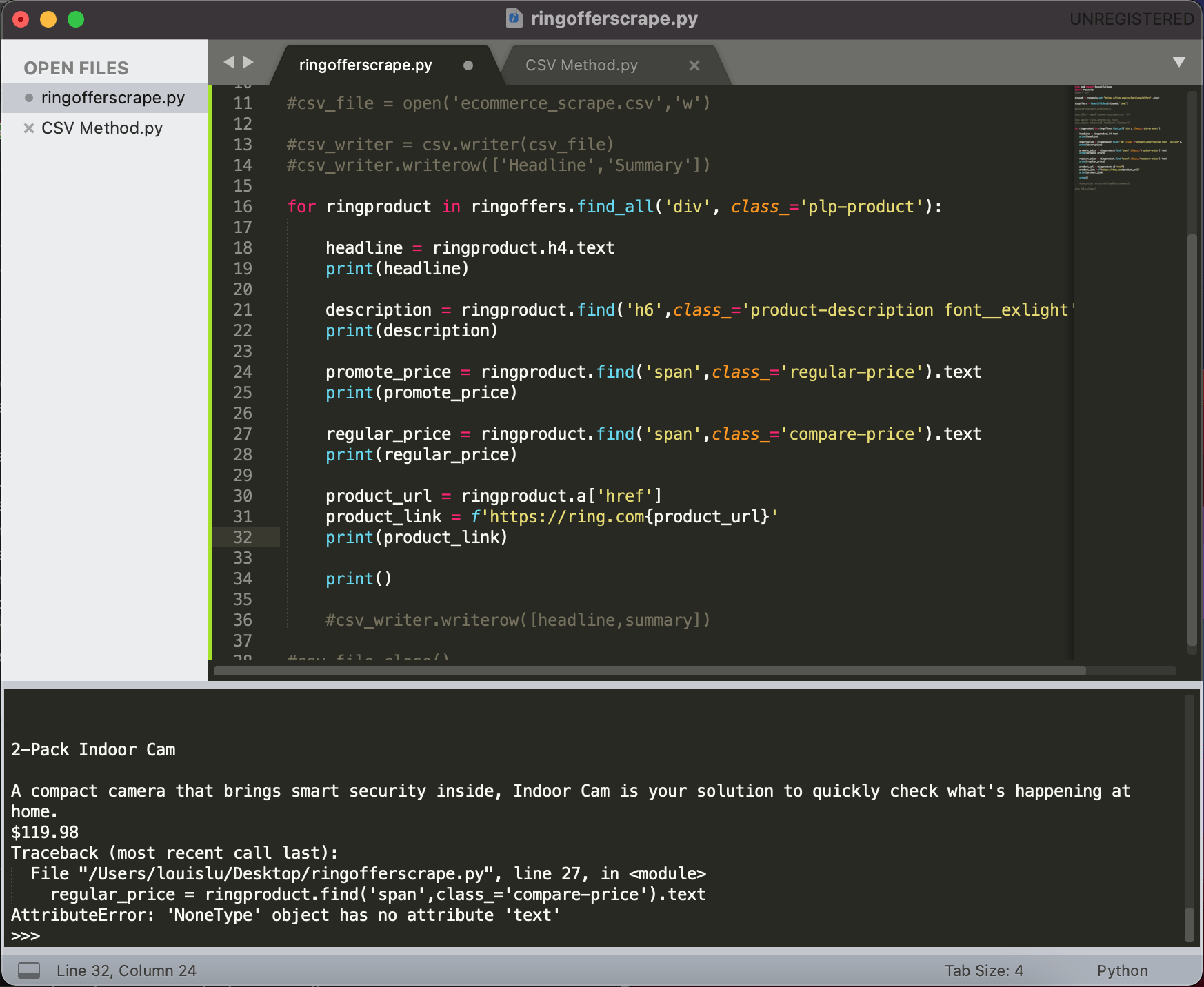
Ensuite, c'est le prix régulier et le prix promotionnel
promote_price = ringproduct.find('span',class_='regular-price').text
print(promote_price)
regular_price = ringproduct.find('span',class_='compare-price').text
print(regular_price)
Enfin et surtout, il s'agit de l'URL de destination du produit.
Lignes de code :
product_url = ringproduct.a['href']
product_link = f'https://ring.com{product_url}'
print(product_link)
Fondamentalement, une seule URL unique apparaît dans le code source de chaque offre groupée de produits. Par exemple, le chemin d’arrivée du kit de démarrage de produit est collections/offres/produits/kit de démarrage. Nous pourrions donc ignorer la valeur que nous souhaitons récupérer et exploiter directement [ ] pour récupérer la valeur href dans une section : product_url = ringproduct.a['href']
Cependant, si nous récupérons ces chemins de données dans un fichier, ils ne peuvent pas être ouverts ni consultés sur la page. Ainsi, pour afficher l'URL complète, nous pouvons créer une variable product_link et exploiter la fonctionnalité de format en utilisant f'' et insérer product_url dans { }.
product_link = f'https://ring.com{product_url}'
Si nous essayons d’imprimer ceci, nous pouvons obtenir un résultat qui prouvera que cela fonctionne.

Créer une boucle pour récupérer toutes les données spécifiées dans la section
Ces lignes de code fonctionnent afin que nous puissions les déployer pour récupérer toutes les données en masse. Pour cela, nous devons utiliser les méthodes for…in et find_all :
for ringproduct in ringoffers.find_all('div', class_='plp-product'):
Comme ce code est au niveau parent, nous devons donc ajouter deux points à la fin de cette ligne de code et mettre en retrait les lignes enfants.
Si nous essayons d'imprimer ceci, nous pouvons voir le résultat ci-dessous, qui comprend toutes les informations sur l'ensemble de produits.
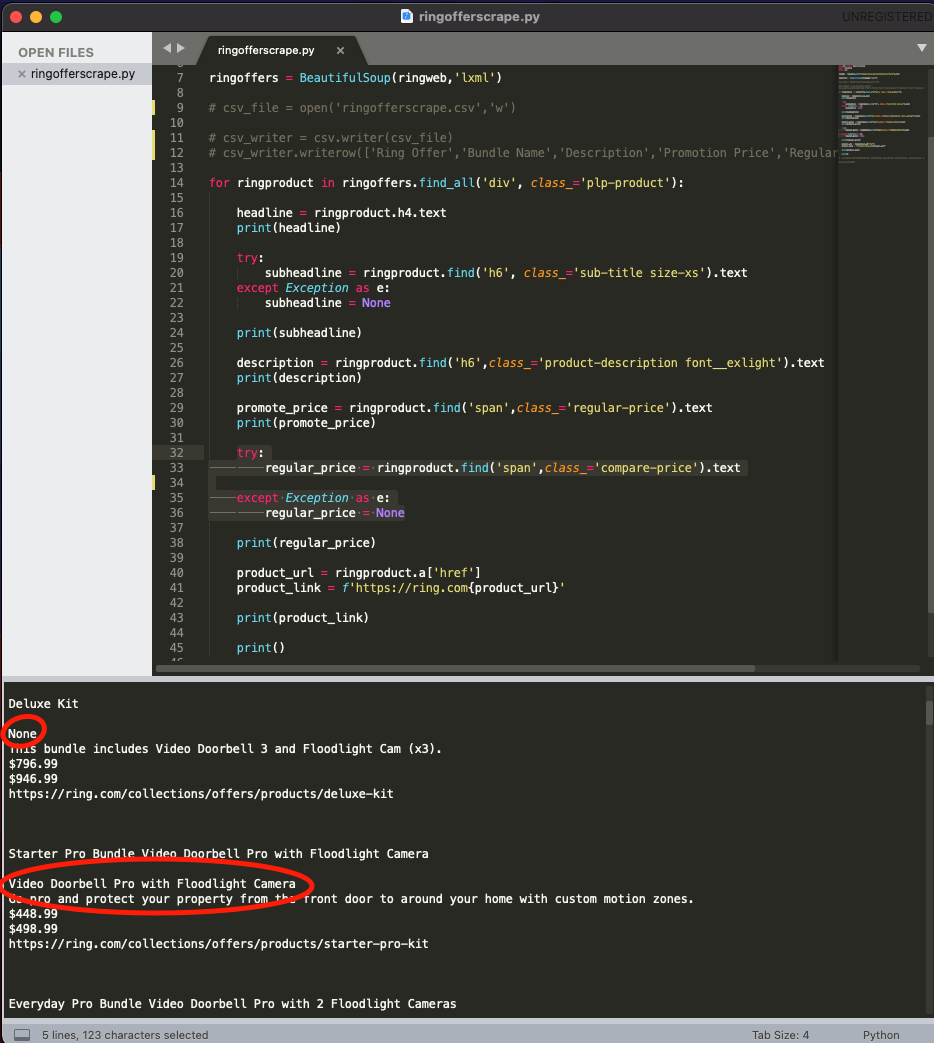
Transmettre les données manquantes dans certaines sections
Vous savez peut-être que toutes les offres groupées de produits n'ont pas de sous-titre et de prix promotionnel, donc si vous essayez d'exécuter des lignes de code de sous-titre et de prix promotionnel si vous rencontrez cette réponse de Python : l'objet n'a pas d'attribut 'text' , et cela arrêterait le processus de grattage.
C’est le reflet du monde du codage car toutes les informations ne sont pas ordonnées et structurées. Nous devons donc utiliser try/sauf pour transmettre cela lors de notre rencontre.
Sous-titre :
try:
subheadline = ringproduct.find('h6', class_='sub-title size-xs').text
except Exception as e:
subheadline = None
Prix promotionnel :
try:
regular_price = ringproduct.find('span',class_='compare-price').text
except Exception as e:
regular_price = None
Pour la valeur de la variable sous sauf exception comme e, vous pouvez la définir comme vous le sentez facile à comprendre, comme aucun, 0, « NA », etc.
Je n'en ai défini aucun, vous pouvez donc voir le résultat de la réponse
Enregistrez les données dans un fichier CSV
Le script python est maintenant prêt et il est temps de sauvegarder les données récupérées dans un emplacement, qui peut êt. re soit un fichier local, soit un serveur en ligne.
Je vais entrer dans les détails du fichier CSV car j'ai déjà parlé de cette leçon. Si vous êtes intéressé, veuillez consulter l'autre article
Chapitre 3 : Utiliser le module CSV pour écrire, analyser et lire des fichiers CSV afin de gérer les données récupérées
Une fois les codes terminés, un fichier CSV comme celui ci-dessous apparaîtra et stockera toutes les données spécifiées que nous souhaitons récupérer.
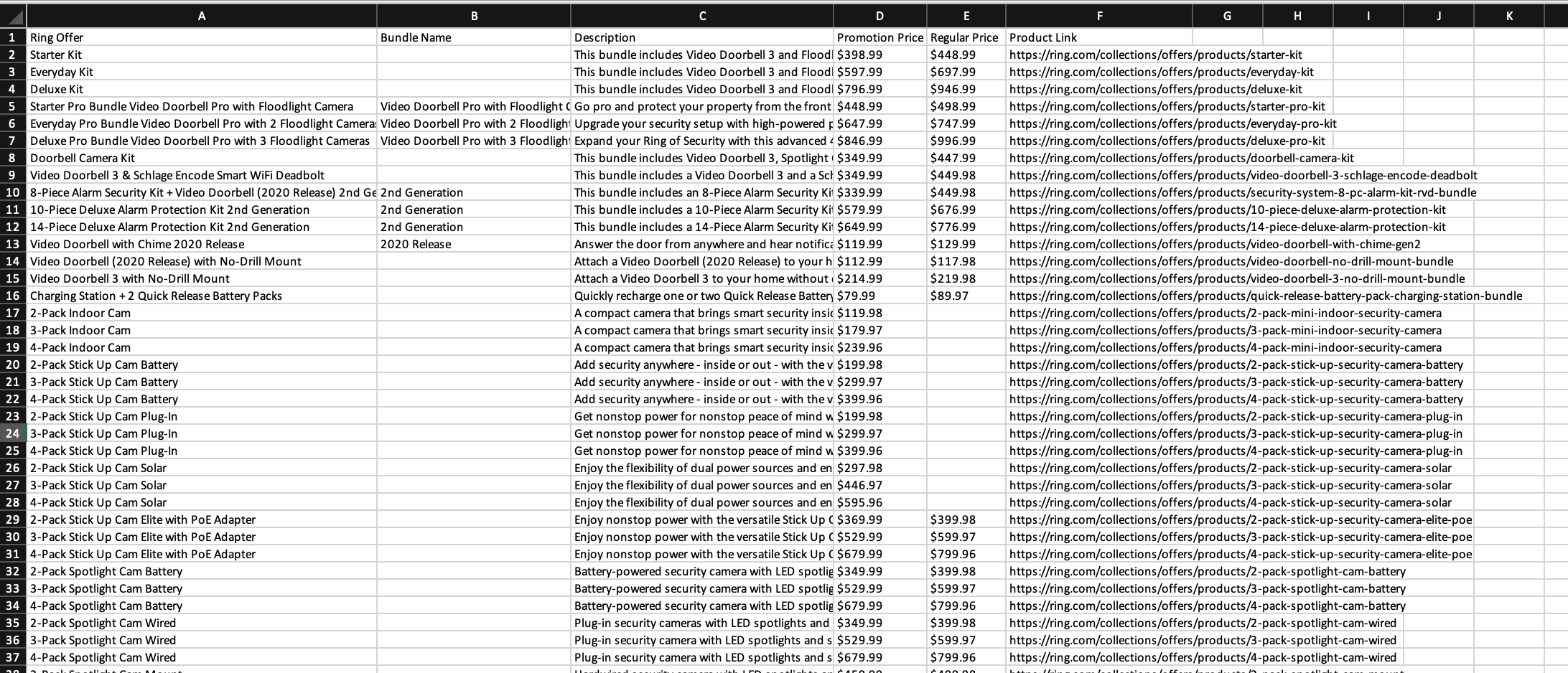
Script Python complet du robot de site Web
Si vous souhaitez disposer de la version complète du script Python de Website Bot, merci de vous inscrire à notre newsletter en ajoutant le message Chapitre 4 . Nous vous enverrons le script immédiatement dans votre boîte aux lettres.
Contactez-nous
Tellement facile, non ? J'espère que vous apprécierez la lecture du chapitre 4 : Créer un robot de site Web pour récupérer des données de site Web spécifiques à l'aide de BeautifulSoup. Si c'est le cas, veuillez nous soutenir en effectuant l'une des choses répertoriées ci-dessous, car cela aide toujours notre chaîne.
- Soutenez et faites un don à notre chaîne via PayPal ( paypal.me/Easy2digital )
- Abonnez-vous à ma chaîne et activez la cloche de notification. Chaîne Youtube Easy2Digital .
- Suivez et aimez ma page Page Facebook Easy2Digital
- Partagez l'article sur vos réseaux sociaux avec le hashtag #easy2digital
- Achetez des produits avec le code de réduction Easy2Digital 10 % ( Easy2DigitalNewBuyers2021)
- Vous vous inscrivez à notre newsletter hebdomadaire pour recevoir les derniers articles, vidéos et codes de réduction d'Easy2Digital
- Abonnez-vous à notre abonnement mensuel via Patreon pour profiter d'avantages exclusifs ( www.patreon.com/louisludigital )
Outre la récupération des données Web HTML et XML, si vous souhaitez apprendre à récupérer certaines données de plate-forme accessibles uniquement via l'API, veuillez consulter cet article, et nous commencerons par la chaîne Youtube.
Chapitre 5 – Créer un robot Youtube pour récupérer les vidéos tendances à l'aide des API Youtube et Easy2Digital
.

