ランダム フォレスト アルゴリズムは多くの業界に適用され、より適切なビジネス上の意思決定を可能にしています。一部のユースケースには、高い信用リスク分析やクロスセルを目的とした製品推奨が含まれます。
この記事では、古典的な赤ワインの品質検証データセットを使用して特徴の重要性を生成するいくつかの方法について簡単に説明します。この章を終えるまでに、ランダム フォレストをプロジェクトに適用し、その結果をさまざまな方法で比較するための基本的な概念を理解できるようになります。
目次: 機械学習における Scikit 学習とランダム フォレストを使用したオブジェクト特徴重要度の生成
- 赤ワインのデータセットとデータ トレーニングの分割
- Scikit-learn による組み込み機能の重要性
- ランダム機能を備えた組み込みの Scikit-learn メソッド
- 順列機能の重要性
- SNAP におけるランダム フォレスト機能の重要性
- ランダム フォレスト パス機能の重要性
- 機能重要度ジェネレーターの完全な Python スクリプト
- データ サイエンスと機械学習 Couresa コースの推奨事項
- よくある質問
赤ワインのデータセットとデータ トレーニングの分割
どのような機械学習モデルにおいても、適切なデータセットを取得するか、データを前処理することが重要です。 Kaggle は、適切なデータセットを検索するための最も人気のあるプラットフォームの 1 つです。赤ワインの品質プロジェクトへのリンクはこちらです。
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
まず、Pandas と Sklearn train_test_split を使用してデータを処理することが最初のステップです。
url = "winequality-red.csv"wine_data = pd . read_csv ( url , sep = ";" )x = wine_data . drop ( 'quality' , axis = 1 )y = wine_data [ 'quality' ]x_train , x_test , y_train , y_test = train_test_split ( x , y , test_size = 0.5 , random_state = 50 )Scikit-learn による組み込み機能の重要性
Scikit-learn は、ランダム フォレスト モデルに組み込みの特徴重要度メソッドを提供します。ドキュメントによると. 、この方法はノードの不純物の減少に基づいています。
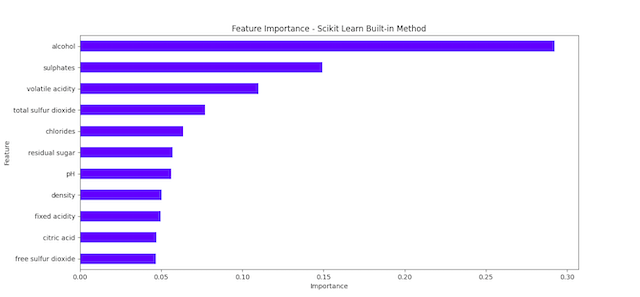
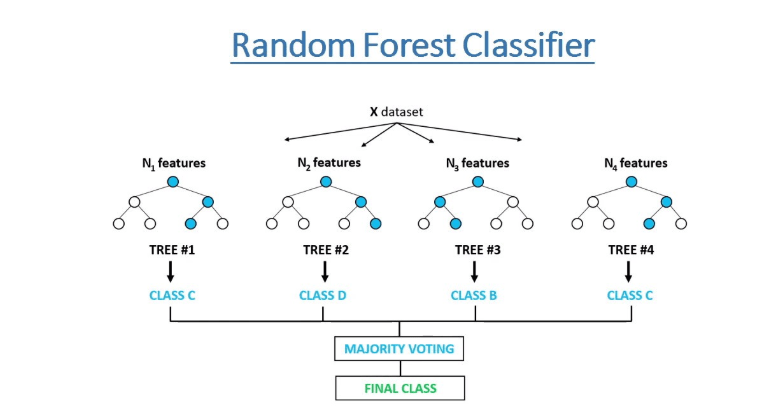
ランダム フォレストでは、質問はモデルの特徴に似ています。いくつかの質問は、他の質問よりも多くの可能性を排除するのに役立ちます。より多くの可能性を迅速に排除するのに役立つ機能は、より早く正解に近づくのに役立つため、より重要であると仮定されています。 Scikit-learn を使用すると、これらの機能の重要性を取得するのは非常に簡単です。
rf = RandomForestRegressor ( n_estimators = 100 , random_state = 50 )rf . fit ( x_train , y_train )inbuilt_importances = pd . Series ( rf . feature_importances_ , index = x_train .columns)inbuilt_importances . sort_values ( ascending = True , inplace = True )inbuilt_importances . plot . barh ( color = 'black' )ランダム機能を備えた組み込みの Scikit-learn メソッド
この方法を進める最も簡単な方法は、データセットにランダムな特徴を追加し、結果がランダムなしの最初の特徴よりも大きく逸脱する可能性があるかどうかを確認することです。
実際の特徴の重要性がランダムな特徴よりも低い場合、その重要性は単なる偶然によるものである可能性があります。
def randomMethod (): X_train_random = x_train .copy() X_train_random [