이번 글에서는 가격 변화와 상관관계가 있을 수 있는 여러 변수를 고려하여 변형 가격을 예측하는 방법을 간략하게 안내하겠습니다. 이 작품이 끝나면 가격 예측을위한 점수 생성을 위해 Python 및 Scikit 학습을 사용하여 비즈니스 실제 사례에 이 모듈을 적용할 수있습니다.
미리 준비해야 할 재료: Numpy, Pandas, Scikit learn, matplotlib, seaborn, Linear Regression, StandardScaler, RandomForest
목차: Python, ScikitLearn을 사용한 다중 변수 기반의 변형 가격 예측
- 데이터세트 로드중
- 데이터 탐색
- 데이터 전처리
- 선형 회귀 모델
- Python, ScikitLearn, 선형 회귀를 사용하여 가격 예측 모델을 구축하는 전체 Python 스크립트
- 데이터 과학 및 기계 학습 Courseresa 추천 과정
데이터세트 로드 중
이 문서에서는 캘리포니아 주택 가격 데이터세트를 예로 사용합니다. 비즈니스 사례 데이터를 데이터 세트로 사용할 수 있다고 합니다. 데이터 세트에 점수를 예측하는 데 더 나은 특정 양의 데이터가 있어야 합니다.
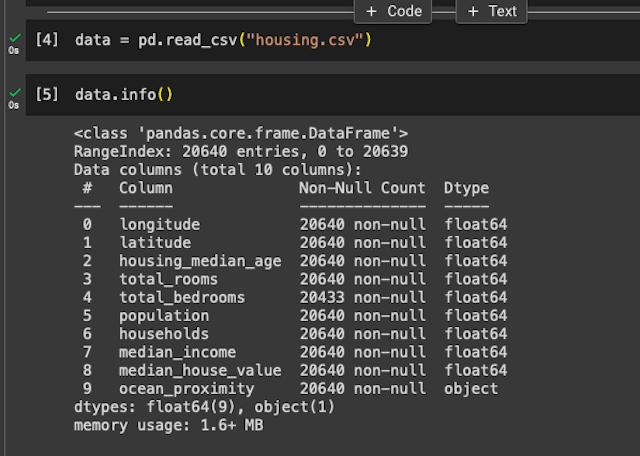
평소와 같이 Pandas를 사용하여 데이터 세트를 로드하고info()를 적용하여 데이터 세트 조건을 한눈에 볼 수 있습니다.
더 나은 예측을 위해 주요 원칙 중 하나는 다양한 측정항목 간의 데이터 크기에 동일한 양의 데이터 행이 있어야 한다는 것입니다. 이 샘플에서 볼 수 있듯이totle_bedrooms 측정항목의 열에는 일부 NA가 표시됩니다. 그러므로 먼저 NA를 삭제해야 합니다.
data.dropna ( inplace= True )데이터 탐색
먼저, 예측할 대상 변형을 설정해야 합니다. 이 경우, 기본적으로 이 실험은 부동산 구매 의사결정을 위한 것이므로 중앙 주택 가치가 목표 변형입니다. 따라서 기존테이블에서 측정항목을 삭제하고 스크립트에서 대상 변형을 새 변수로 별도로 설정해야 합니다.
X = data.drop ([ 'median_house_value' ], axis= 1 )
y = data [ 'median_house_value' ]그런 다음 각 변수와 대상 변형의 상관 관계를 탐색하고 데이터 세트가 적합한지 이해하는 큰 그림을 가질 수 있습니다.
일반적으로 이 목적을 달성하기 위해 전체 데이터세트를 사용할 필요는 없습니다. 이 경우 열차 테스트 분할을 다시 활용할 수 있습니다. 우리는 이전 장에서 이 방법을 자세히 설명했습니다. 관심이 있으시면 Easy2Digital.com의 다른 장을 살펴보십시오.
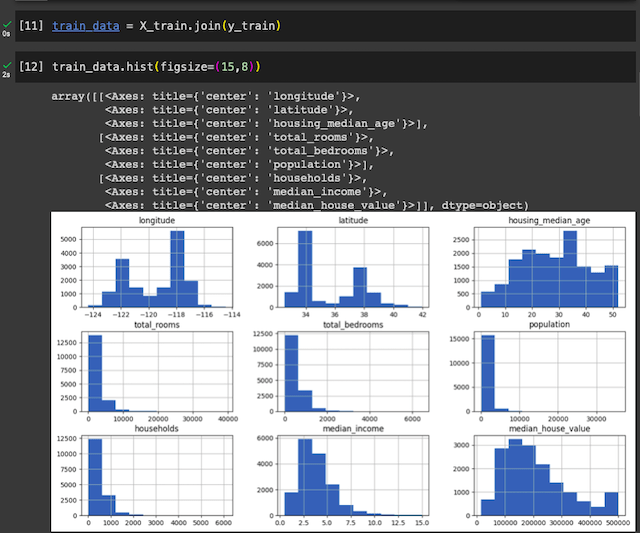
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size= 0.2 )그런 다음, Join() 및 hist() 메소드를 사용하여 히스토그램 그래프에 표시해 볼 수 있습니다.
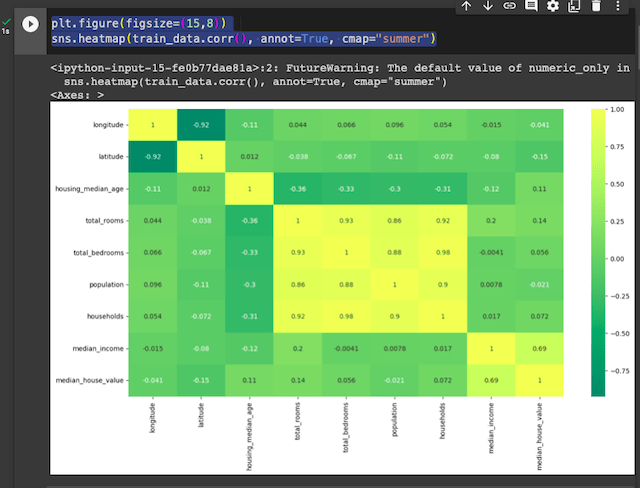
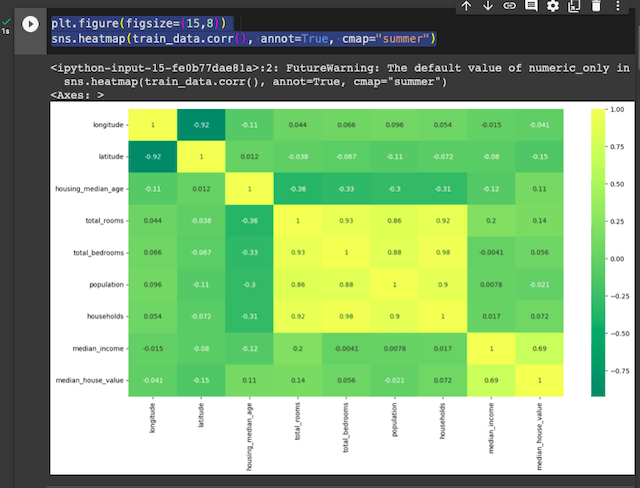
또는 corr() 메서드를 사용하여 히트맵에 표시할 수 있는데, 이는 깊고 밝은 색상 대비로 더욱 시각적입니다.
데이터 전처리
우리는 다양한 주요 변수를 볼 수 있습니다. 게다가 위의 히스토그램 분포를 보면 일부 특징이 합리적이지 않은 것처럼 보입니다. 따라서 우리는 특성 변수 분포가 더좋을 수 있는지 확인하기 위해 log()를 사용해 볼 수 있습니다.
train_data [ 'total_rooms' ] = np.log ( train_data [ 'total_rooms' ] + 1 )
train_data [ 'total_bedrooms' ] = np.log ( train_data [ 'total_bedrooms' ] + 1 )
train_data [ 'population' ] = np.log ( train_data [ 'population' ] + 1 )
train_data [ 'households' ] = np.log ( train_data [ 'households' ] + 1 )이 경우에는 로그 메소드를 구현한 후에 더 의미가 있습니다. 일부 기능이 0일 수 있는 경우를 대비해 로그에 1을 더해야 합니다.
그런 다음 데이터 전처리의 또 다른 중요한 부분은 문자열 데이터 유형을 정수로 변환하는 것입니다. 머신러닝은 숫자 기반 프로세스이고 문자열을 직접 처리할 수없기 때문입니다.
데이터세트에서 해양 근접성은 문자열 데이터 형식 형식으로되어 있음을 알 수 있습니다. 따라서 우리는 panda get_dummies 메소드를 사용하여 이를 처리할 수있습니다.
pd.get_dummies ( train_data.ocean_proximity )선형 회귀 모델을 사용하여 예측
이제 데이터세트가 준비되었으며 모델을 가져오고 기능 데이터세트를 확장하여 주택 가치를 예측하기 위한 모델 정확도를 테스트할 수 있습니다.
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler ()
X_train , y_train = train_data.drop ([ 'median_house_value' ], axis= 1 ), train_data [ 'median_house_value' ]
X_train_s = scaler.fit_transform ( X_train )
reg = LinearRegression ()
reg.fit ( X_train_s , y_train )
LinearRegression ()
test_data = X_test.join ( y_test )
test_data [ 'total_rooms' ] = np.log ( test_data [ 'total_rooms' ] + 1 )
test_data [ 'total_bedrooms' ] = np.log ( test_data [ 'total_bedrooms' ] + 1 )
test_data [ 'population' ] = np.log ( test_data [ 'population' ] + 1 )
test_data [ 'households' ] = np.log ( test_data [ 'households' ] + 1 )
test_data = test_data.join ( pd.get_dummies ( test_data.ocean_proximity )) .drop ([ 'ocean_proximity' ], axis= 1 )
X_test , y_test = test_data.drop ([ 'median_house_value' ], axis= 1 ), test_data [ 'median_house_value' ]
X_test_s = scaler.transform ( X_test )
reg.score ( X_test_s , y_test )Python, ScikitLearn을 사용하여 다중 변수를 기반으로 가격 예측 모델을 구축하는 전체 Python 스크립트
Python을 사용하여 가격 예측 모델 구축, ScikitLearn, 선형 회귀, '가격 예측 모델'이라는 메시지를 추가하여 뉴스레터를 구독 하세요. . 우리는 즉시 귀하의 사서함으로 스크립트를 보내드립니다.
Python, ScikitLearn, 선형 회귀를 사용하여 가격 예측 모델 구축을 재미있게 읽어보시기 바랍니다. 그렇게 했다면 아래 나열된 일 중 하나를 수행하여 우리를 지원해 주세요. 이는 항상 우리 채널에 도움이 되기 때문입니다.
- PayPal( paypal.me/Easy2digital )을 통해채널을 지원하고 기부하세요.
- 내 채널을 구독하고 Easy2Digital Youtube 채널 알림 벨을 켜십시오.
- 내 페이지 Easy2Digital Facebook 페이지를 팔로우하고 좋아요를 누르세요.
- 해시태그 #easy2digital을 사용하여 소셜 네트워크에 기사를 공유하세요.
- Easy2Digital 최신 기사, 비디오 및 할인 코드를 받으려면 주간 뉴스레터에 가입하세요.
- Patreon을 통해 월간 멤버십을 구독하여 독점적인 혜택을 누리세요( www.patreon.com/louisludigital )
