
Amazon product information in the search result has great value for you to understand 2 things. They are the sales performance of a product and the customer review on this product and merchant. Then, it can extend to a much wider application, such as the price tracker, and P&L market value.
이 장에서는 Amazon 제품 스크레이퍼를 만들고 Google 시트에 가져온 데이터를 저장하는 방법을 알려 드리겠습니다. 이 장의 끝까지GSPread 모듈을 설치하는 방법과 HTML에서 데이터 요소를 찾을 위치를 배울 수 있습니다.
목차 : Selenium, BeautifulSoup 및 Easy2Digital API를 사용한 Amazon Product Scraper
- 셀레늄을 가져옵니다
- 제품 검색 스크레이퍼의 프로토 타입을 만듭니다
- 검색 결과의 다중 페이지를 긁습니다
- 가져온 데이터 세트를 Google 시트에 저장하십시오
- 아마존 제품 스크레이퍼 전체 파이썬 스크립트
- 자주하는 질문
- 아마존 최신 트렌드 API 엔드 포인트 권장 사항
Amazon Product Scraper – Import Selenium, BeautifulSoup, and gspread Module
파이썬 스크립트에서 BeautifulSoup을 사용하여 웹 사이트를 방문 할 수는 없습니다. “죄송합니다, 뭔가 잘못”의 결과로 나타날 것입니다. 대신 셀레늄을 사용하는 것처럼 제품 데이터를 원활하게 가져올 수 있습니다. 이 두 모듈을 가져 오는 것은 다른 봇에 대해 이전 스크립트와 동일한 프로세스입니다.
또한이 스크립트는 시트에 제품 정보를 가져오고 저장하기위한 것이 아닙니다. 또한 일정으로 데이터를 자동으로 새로 고치고 경쟁 업체의마케팅 정보 및 제품 가격을 추적하는 것을 목표로합니다. 가격 추적기의 경우 다른 기사를 발표 할 것입니다. 이 때문에 Google 시트 API를 사용하고 Google 시트의 데이터를 관리하는 것이 좋습니다. 여기서는 GSPread를 사용하는 것이 좋습니다.
Google 시트 API를 만들고 서비스 계정을 설정하려면 다른 기사를 참조하십시오. 나는 이전에 기사를 발표했다. 자세한 내용은이 기사를 확인하십시오.
Easy2Digital Google Sheets API는 Google API에 연결하고 Fetched 데이터를 관리하기가 훨씬 쉽다고 말합니다. 먼저 먼저 무료Easy2Digital API 토큰을 신청해야합니다.
그런 다음 새로운 Google API 서비스 계정에서 다운로드 한 JSON 키 이름을 복사하여 Easy2Digital API GoogleJsonParameter와 연결된 스크립트에 붙여 넣습니다.
<. p class="ud-blog-details-para">자세한 내용은 API 문서를 참조하십시오.Amazon Product Scraper – 제품 검색 스크레이퍼 프로토 타입 생성
검색 쿼리를 사용하여 제품의 정보를 검색 할 수 있습니다. 기본적으로 아래는 검색하는 제품이든 Amazon Product Scraper의 프로토 타입입니다. 또는 Amazon 시장이 어디에서나보고 있습니다.
1. Amazon 검색 쿼리 URL 구조
URL에 SERP를 제어하는 두 가지 매개 변수가있을 수 있습니다. 하나는 K와 키워드가 이어집니다. 다른 하나는 페이지가 페이지 번호와 함께 이어졌습니다.
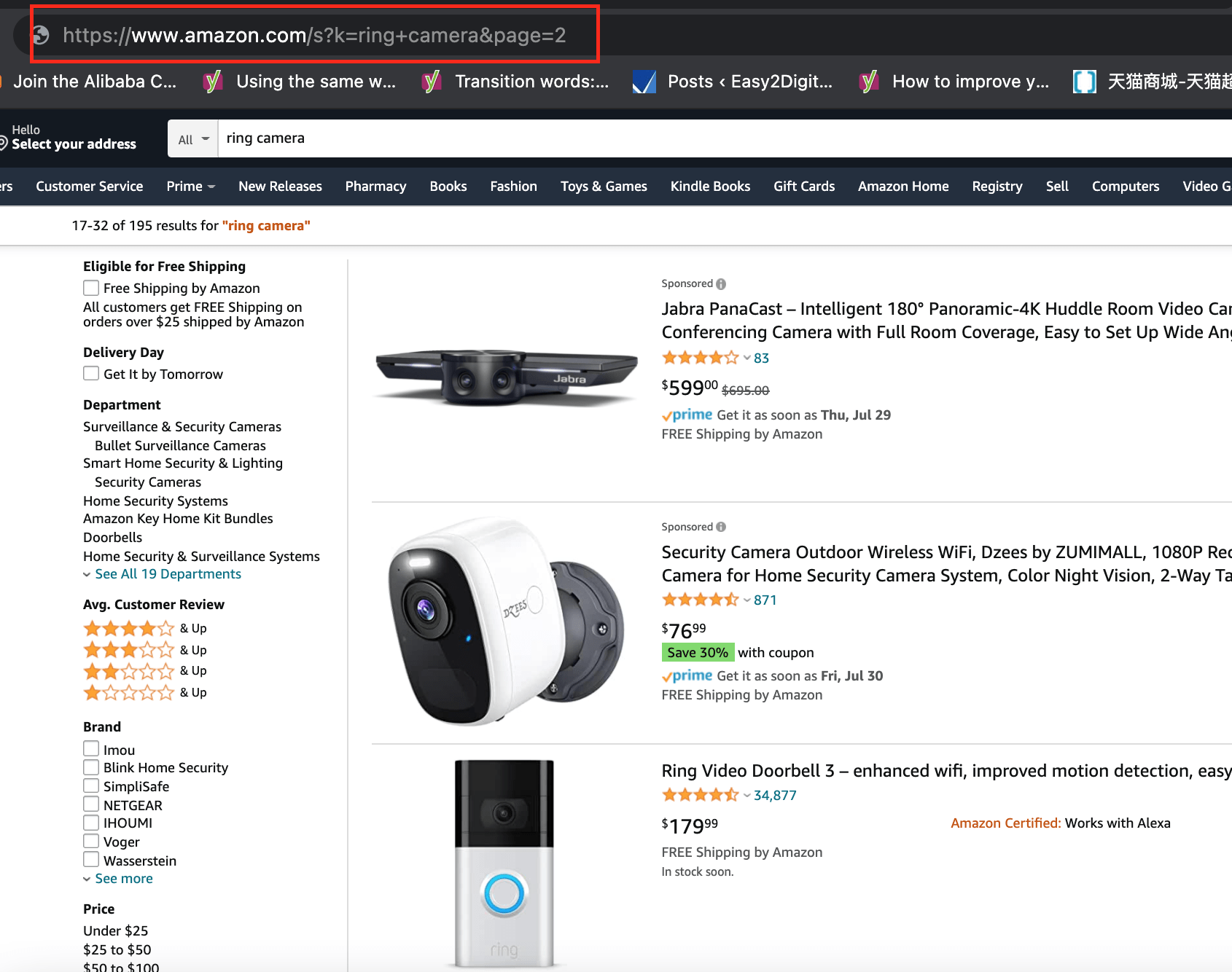
https://www.amazon.com/s?k=ring+camera&page=2
따라서 나중에 사용을 위해 두 가지 변수를 만들 수 있습니다. 하나는 검색하는 키워드를 나타냅니다. 하나는 더 많은 페이지를 동적으로 반복하고 가져 오는 것입니다
query = "ring+camera"page = "&page="
2. SERP에서 제품 정보 블록을 찾으십시오
제품 제목을 마우스 오른쪽 단추로 클릭하고 검사 기능을 사용할 수 있습니다. 전체 제품 정보 블록을 찾을 수있는 요소를 알 수 있습니다. 블록에는 가져 오려는 모든 핵심 제품 정보가 포함되어 있습니다. 예를 들어, 그들은 ASIN, 가격, 제목, URL, 검토 수 등입니다. 이전에 공유했던 웹 스크래핑과 유사합니다.
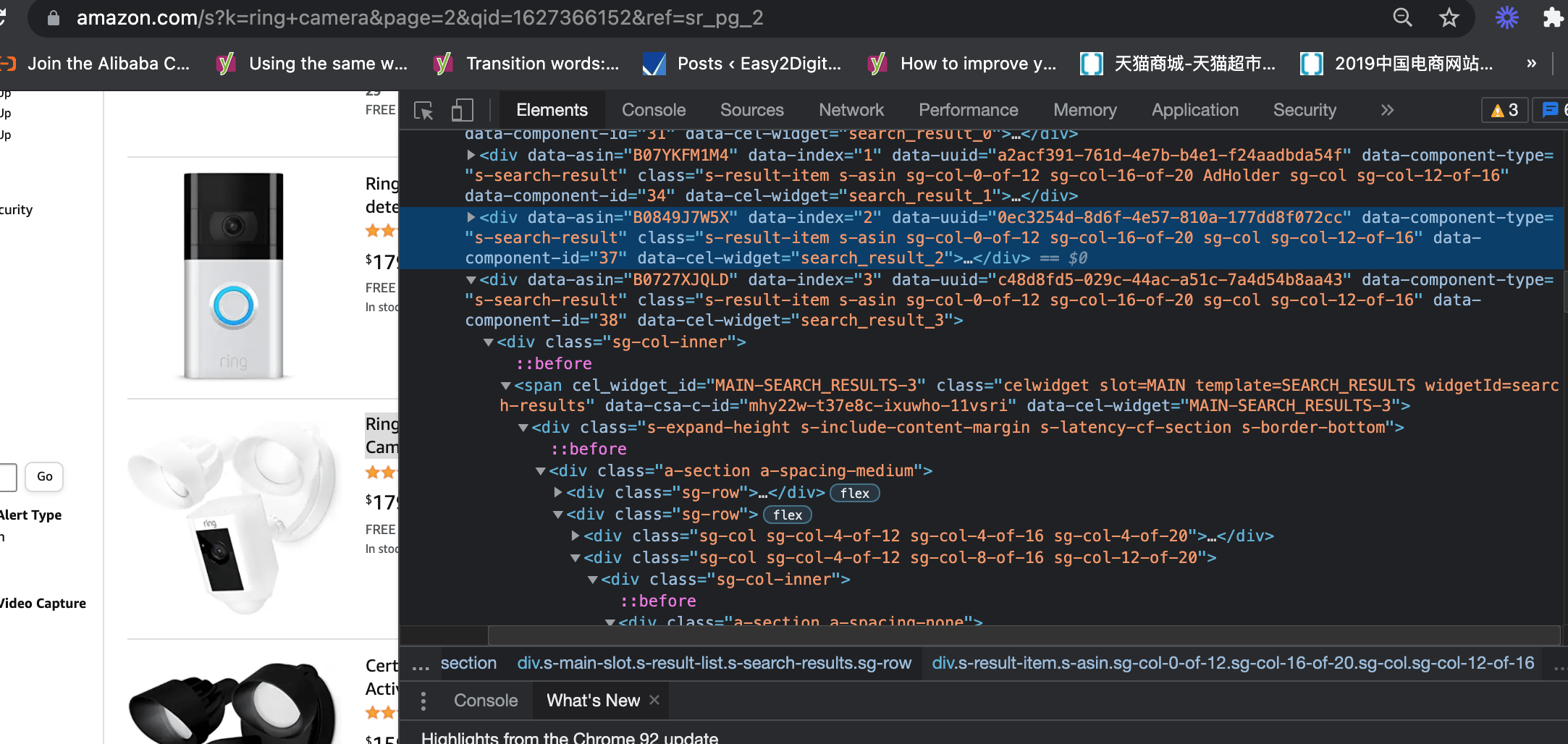
보시다시피, 모든 정보는 DIV와 데이터 구성 요소 유형이라는 태그에 있습니다. 따라서 이와 같은 코드를 작성할 수 있습니다. 이것은 첫 페이지를 긁어 내기위한 것입니다
driver.get("https://www.amazon.com/s?k=querysoup = BeautifulSoup(driver.page_source, 'html.parser')results = soup.find_all('div',{'data-component-type': 's-search-result'})
3. 데이터 유형을 선택하고 구체적으로 스크랩합니다
ASIN is a key element you must fetch because the price tracker needs this element to connect with your current P&L calculator. I would talk about this in the other article.
보시다시피, Asin 값은이 태그 데이터에 앉아 있습니다. 따라서 변수를 만들고 attrs를 사용하여 각 제품의 ASIN 번호를 얻을 수 있습니다.
asins = item.attrs['data-asin']
그런 다음 제품 제목은 HTML의 H2입니다. 따라서 파이썬 코드는 다음과 같습니다. 그러나 모든 선행 (처음의 공간) 및 끝의 후행 (공간) 문자를 제거하려면 텍스트 후에 Strip ()를 사용할 수 있습니다.
try: title = item.h2.a.text.strip()except Exception as e: raise None
가격은 동적이며 경쟁 업체의 프로모션에 따라 변할 수 있기 때문에 가격 추적기의 또 다른 핵심 요소입니다. 따라서 Amazon Product Scraper 에서이 코딩은 가격을 가져 오는 데 도움이 될 수 있습니다. 그러나 나중에 시장 가치를 필터링 및 계산하려면 통화 신호를 제거하는 것이 좋습니다. 이는 데이터가 Google 시트의 숫자 형식인지 확인하기위한 것입니다.
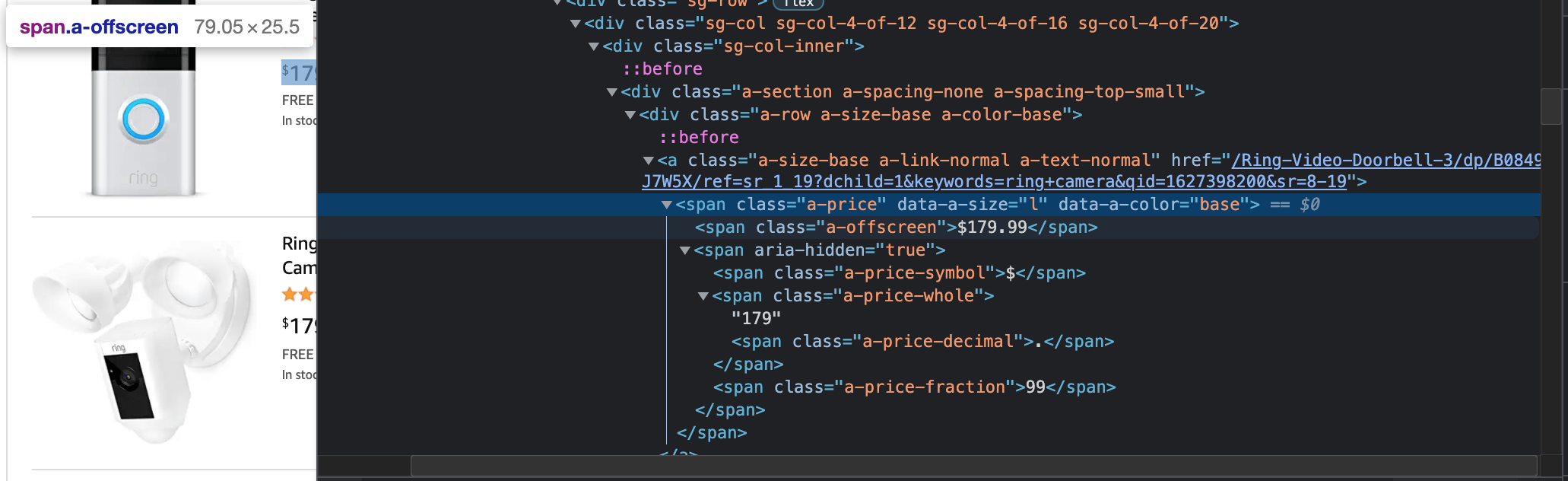
try: price_parent = item.find('span','a-price') price = price_parent.find('span','a-offscreen').text.replace('$','')except Exception as e: price_parent = '0' price = '0'
Amazon Product Scraper – Scrape Multi-pages of Search Result
Amazon SERP의 첫 번째 페이지에는 AVG.22 제품이 있습니다. 제품의 시장 성능과 기회를 이해하는 것만으로는 충분하지 않을 수 있습니다. 이 경우 둘 이상의 페이지를 긁어 야합니다. 운 좋게도 복잡하지 않으며 이전에 공유 한 웹 페이지 매김 스크레이퍼와 비슷합니다.
먼저, 특정 데이터 페치 루핑보다 높은 계층에 루프를 만들어야합니다. 변수 X를 만들 수 있습니다.
그런 다음 범위에서 페이지 수를 설정할 수 있습니다. 그러나 마지막 페이지는 y – 1이어야한다는 점을 명심하십시오. 예를 들어, 마지막 페이지는 3이므로 마지막 페이지는 2임을 의미합니다.
for x in range (1,3): driver.get("https://www.amazon.com/s?k="+query+page+str(x)) soup = BeautifulSoup(driver.page_source, 'html.parser') results = soup.find_all('div',{'data-component-type': 's-search-result'})
for item in results:
asins = item.attrs['data-asin']
마지막으로 Amazon URL 구조를 알고 있듯이 URL 요청을 업데이트해야합니다.
driver.get("https://www.amazon.com/s?k="+query+page+str(x))
가져온 데이터를 Google 시트에 저장하십시오
이제 상황이 준비되었고 이제 Google 시트에 먹이를주고 저장할 차례입니다. “Post”메소드를 사용하고 Easy2Digital API 매개 변수에 각각 두 변수로 셀 위치를 가진 페치 된 데이터 및 특정 시트 탭을 추가해야합니다.
아마존 제품 스크레이퍼의 전체 파이썬 스크립트
If you would like to have the full version of the Python Script of Amazon Product Scraper, please subscribe to our newsletter by adding the message “Chapter 16”. We would send you the script immediately to your mailbox.
16 장 – 셀레늄, BeautifulSoup 및 Easy2Digital API를 사용하여 Amazon Product Scraper를 읽는 것을 즐기시기 바랍니다. 당신이 그렇게했다면, 아래에 나열된 것들 중 하나를 수행하여 항상 우리의 채널을 도울 수 있기 때문에 우리를 지원하십시오.
- Support and donate to our channel through PayPal (paypal.me/Easy2digital)
- Subscribe to my channel and turn on the notification bell Easy2Digital Youtube channel.
- Follow and like my page Easy2Digital Facebook page
- 해시 태그 #easy2digital과 함께 소셜 네트워크에 기사를 공유하십시오.
- Buy products with Easy2Digital 10% OFF Discount code (Easy2DigitalNewBuyers2021)
- Easy2Digital 최신 기사, 비디오 및 할인 코드를 받으려면 주간 뉴스 레터에 가입하십시오.
- Subscribe to our monthly membership through Patreon to enjoy exclusive benefits (www.patreon.com/louisludigital)
