在本文中,我将简要介绍如何根据考虑可能与定价变化相关的多个变量来预测变体定价。在本文结束时,您可以使用 Python 和 Scikit learn 将此模块应用到您的业务实际案例中,以生成分数来预测定价。
提前准备的材料:Numpy、Pandas、Scikit learn、matplotlib、seaborn、Linear Regression、StandardScaler、RandomForest
目录:使用 Python、ScikitLearn 基于多个变量的变体价格预测
加载数据集
本文以加州房价数据集为例。据说您可以使用业务案例数据作为数据集。只需确保数据集应具有一定数量的数据,这样可以更好地预测分数。
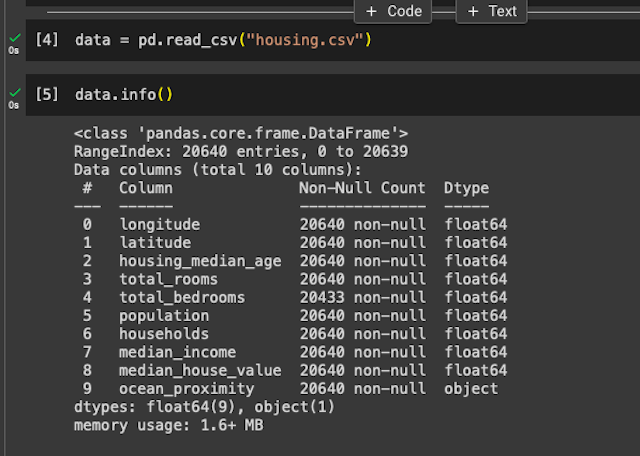
像往常一样,我们可以使用 Pandas 加载数据集并应用 info() 来查看数据集的情况。
为了更好的预测,主要原则之一是不同指标之间的数据大小应具有相同数量的数据行。正如您从该示例中看到的,显然 totle_bedrooms 指标在其列中显示了一些 NA。因此,我们需要先去掉NA。
data.dropna ( inplace= True )数据探索
首先,我们需要设置一个目标变量来预测。在这种情况下,住房中位值是目标变量,因为基本上这个实验是为了做出房产购买决策。因此,我们需要从现有表中删除指标,并将目标变体单独设置为脚本中的新变量。
X = data.drop ([ 'median_house_value' ], axis= 1 )y = data [ 'median_house_value' ]然后,我们可能会尝试探索每个变量与目标变体的相关性,并全面了解数据集是否有意义。
通常我们不需要使用整个数据集来实现此目的。在这种情况下,我们可以再次利用训练测试分割。我们在上一章详细阐述了这个方法。如果您有兴趣,请探索 Easy2Digital.com 上的其他章节
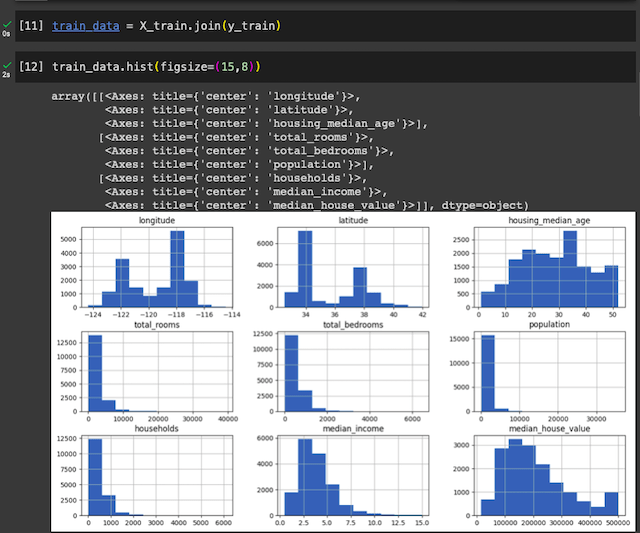
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_siz. e= 0.2 )然后,我们可以尝试使用 join() 和 hist() 方法在直方图中显示它们
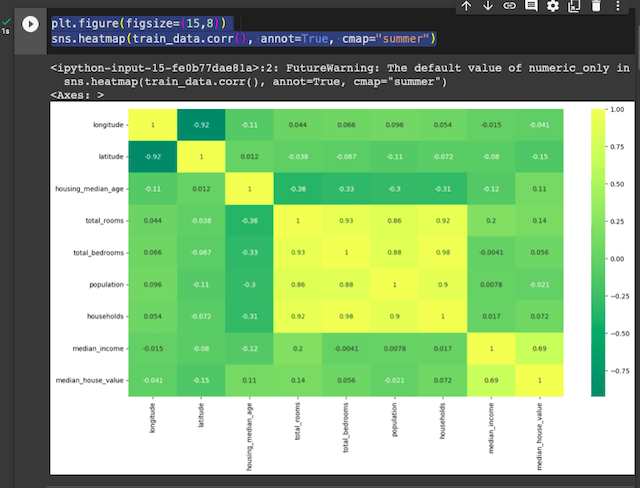
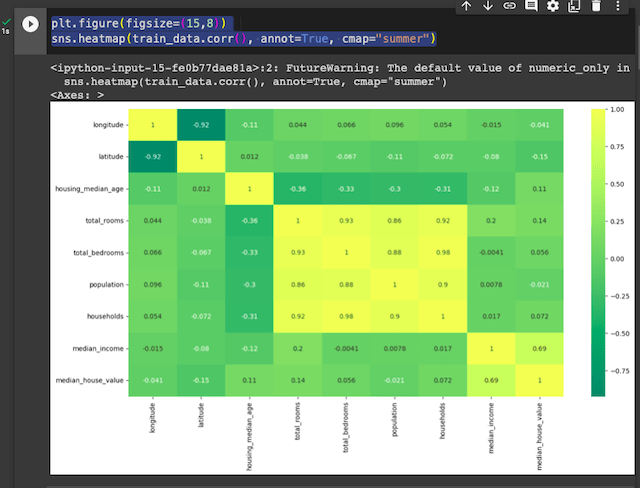
或者我们可以使用 corr() 方法在热图中显示,通过深浅颜色对比更加直观。
数据预处理
我们可以看到一堆特色变量。此外,当我们查看上面的直方图分布时,一些特征看起来不合理。所以我们可能会尝试使用 log() 来看看特征变量分布是否可以更好。
train_data [ 'total_rooms' ] = np.log ( train_data [ 'total_rooms' ] + 1 )train_data [ 'total_bedrooms' ] = np.log ( train_data [ 'total_bedrooms' ] + 1 )train_data [ 'population' ] = np.log ( train_data [ 'population' ] + 1 )train_data [ 'households' ] = np.log ( train_data [ 'households' ] + 1 )在这种情况下实现 log 方法后就更有意义了。我们需要在日志中加一,因为以防万一某些功能可能为零。
然后,数据预处理的另一个关键部分是将字符串数据类型转换为整数。这是因为机器学习是一个数字驱动的过程,它无法直接处理字符串。
在数据集中,我们发现海洋邻近度采用字符串数据类型格式。因此,我们可以使用 panda get_dummies 方法来处理这个问题。
pd.get_dummies ( train_data.ocean_proximity )使用线性回归模型进行预测
现在数据集已经就位,我们可以尝试导入模型并通过缩放要素数据集来测试模型预测住房价值的准确性。
from sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import StandardScalerscaler = StandardScaler ()X_train , y_train = train_data.drop ([ 'median_house_value' ], axis= 1 ), train_data [ 'median_house_value' ]X_train_s = scaler.fit_transform ( X_train )reg = LinearRegression ()reg.fit ( X_train_s , y_train )LinearRegression ()test_data = X_test.join ( y_test )test_data [ 'total_rooms' ] = np.log ( test_data [ 'total_rooms' ] + 1 )test_data [ 'total_bedrooms' ] = np.log ( test_data [ 'total_bedrooms' ] + 1 )test_data [ 'population' ] = np.log ( test_data [ 'population' ] + 1 )test_data [ 'households' ] = np.log ( test_data [ 'households' ] + 1 )test_data = test_data.join ( pd.get_dummies ( test_data.ocean_proximity )) .drop ([ 'ocean_proximity' ], axis= 1 )X_test , y_test = test_data.drop ([ 'median_house_value' ], axis= 1 ), test_data [ 'median_house_value' ]X_test_s = scaler.transform ( X_test )reg.score ( X_test_s , y_test )使用 Python、ScikitLearn 构建基于多变量的价格预测模型的完整 Python 脚本
如果您对使用 Python、ScikitLearn、线性回归构建定价预测模型感兴趣,请添加消息“价格预测模型”来订阅我们的新闻通讯。我们会立即将脚本发送到您的邮箱。
我希望您喜欢阅读使用 Python、ScikitLearn、线性回归构建定价预测模型。如果您这样做了,请通过执行下列操作之一来支持我们,因为这总是对我们的频道有所帮助。
- 通过 PayPal ( paypal.me/Easy2digital ) 支持并捐赠我们的频道
- 订阅我的频道并打开通知铃Easy2Digital Youtube 频道。
- 关注并喜欢我的页面Easy2Digital Facebook 页面
- 使用主题标签 #easy2digital 在您的社交网络上分享文章
- 您订阅我们的每周通讯即可接收 Easy2Digital 最新文章、视频和折扣代码
- 通过 Patreon 订阅我们的月度会员即可享受独家优惠 ( www.patreon.com/louisludigital )
