Gerar importância de recursos usando o scikit learn, floresta aleatória
Aprenda um conceito básico para usar a floresta aleatória aplicada aos seus projetos e comparar o resultado entre diferentes métodos
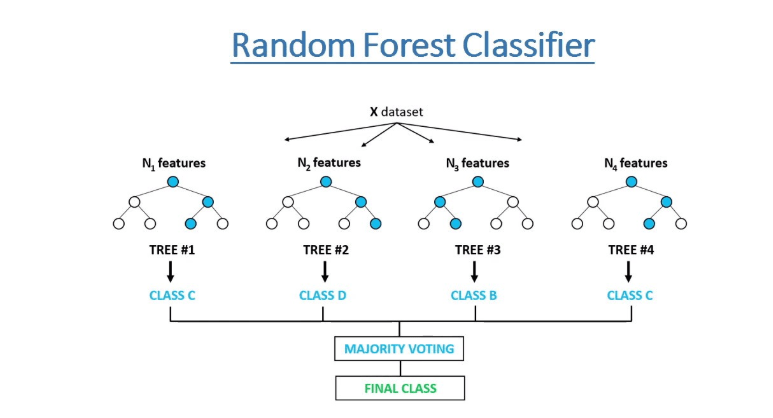
O algoritmo de floresta aleatória foi aplicado em vários setores, permitindo-lhes tomar melhores decisões de negócios. Alguns casos de uso incluem análise de alto risco de crédito e recomendação de produtos para fins de venda cruzada.
Neste artigo, eu explicaria brevemente vários métodos para gerar a importância do recurso usando o conjunto de dados clássico do validador de qualidade do vinho tinto. Ao final deste capítulo, você poderá ter um conceito básico para usar o Random Forest aplicado aos seus projetos e comparar o resultado entre diferentes métodos.
Índice: Gere a importância do recurso do objeto usando Scikit learn e Random Forest no aprendizado de máquina
- Conjunto de dados de vinho tinto e divisão de treinamento de dados
- Importância do recurso integrado com Scikit-learn
- Método Scikit-learn integrado com um recurso aleatório
- Importância do recurso de permutação
- Importância do recurso Random Forest com SNAP
- Importância do recurso Random Forest Path
- Scripts Python completos do gerador de importância de recursos
- Recomendação do curso Couresa de Ciência de Dados e Aprendizado de Máquina
- Perguntas frequentes
Conjunto de dados de vinho tinto e divisão de treinamento de dados
Para qualquer modelo de aprendizado de máquina, é fundamental obter um conjunto de dados adequado ou pré-processar os dados. Kaggle é uma das plataformas mais populares para você pesquisar um conjunto de dados adequado. Aqui está o link para o projeto de qualidade do vinho tinto.
https://www.kaggle.com/datasets/uciml/red-wine-quality-cortez-et-al-2009
Em primeiro lugar, processar os dados usando Pandas e Sklearn train_test_split é o primeiro passo.
url = "winequality-red.csv"
wine_data = pd . read_csv ( url , sep = ";" )
x = wine_data . drop ( 'quality' , axis = 1 )
y = wine_data [ 'quality' ]
x_train , x_test , y_train , y_test = train_test_split ( x , y , test_size = 0.5 , random_state = 50 )
Importância do recurso integrado com Scikit-learn
Scikit-learn fornece um método integrado de importância de recurso para modelos Random Forest. Segundo a documentação, este método é baseado na diminuição da impureza do nó.

Em uma Floresta Aleatória, as questões são como os recursos do modelo. Algumas perguntas ajudam a eliminar mais possibilidades do que outras. A suposição é que os recursos que ajudam a eliminar mais possibilidades rapidamente são mais importantes porque ajudam você a se aproximar da resposta correta com mais rapidez. É muito simples obter essas importâncias de recursos com o Scikit-learn:
rf = RandomForestRegressor ( n_estimators = 100 , random_state = 50 )
rf . fit ( x_train , y_train )
inbuilt_importances = pd . Series ( rf . feature_importances_ , index = x_train .columns)
inbuilt_importances . sort_values ( ascending = True , inplace = True )
inbuilt_importances . plot . barh ( color = 'black' )
Método Scikit-learn integrado com um recurso aleatório
A maneira mais simples de avançar neste método é adicionar um recurso aleatório ao conjunto de dados e ver se o resultado pode ser desviado mais do que o primeiro sem aleatório.
Se uma característica real tiver menor importância do que a característica aleatória, isso pode indicar que sua importância se deve apenas ao acaso.
def randomMethod ():
X_train_random = x_train .copy()
X_train_random [ "RANDOM" ] = np . random . RandomState ( 42 ). randn ( x_train .shape[ 0 ])
rf_random = RandomForestRegressor ( n_estimators = 100 , random_state = 42 )
rf_random . fit ( X_train_random , y_train )
importances_random = pd . Series ( rf_random . feature_importances_ , index = X_train_random .columns)
importances_random . sort_values ( ascending = True , inplace = True )
importances_random . plot . barh ( color = 'blue' )
plt . xlabel ( "Importance" )
plt . ylabel ( "Feature" )
plt . title ( "Feature Importance - Scikit Learn Built-in with random" )
plt . show ()
return
Importância do recurso de permutação
A importância do recurso de permutação é outra técnica para estimar a importância de cada recurso em um modelo Random Forest, medindo a mudança no desempenho do modelo quando os valores do recurso são embaralhados aleatoriamente.
Uma das vantagens deste método é que ele pode ser utilizado com qualquer modelo, não apenas com Random Forests, o que torna os resultados entre modelos mais comparáveis.
Importância do recurso Random Forest com SNAP
SHAP é um método para interpretar a saída de modelos de aprendizado de máquina baseados na teoria dos jogos.
Ele fornece uma medida unificada da importância do recurso que, assim como a importância da permutação, pode ser aplicada a qualquer modelo.
A principal desvantagem é que pode ser computacionalmente caro, especialmente para grandes conjuntos de dados ou modelos complexos.
Importância do recurso Random Forest Path

Outra maneira de entender como cada recurso contribui para as previsões da Random Forest é observar os caminhos da árvore de decisão que cada instância segue.
Ele calcula a diferença entre o valor de predição no nó folha e os valores de predição nos nós que o precedem para obter a contribuição estimada de cada recurso.
Script Python completo do gerador de importância de recursos
Se você estiver interessado no Capítulo 76 – Gerar a importância do recurso do objeto usando Scikit learn e Random Forest, assine nossa newsletter adicionando a mensagem 'Capítulo 75 + API de noção' . Enviaremos o script imediatamente para sua caixa de correio.
Espero que você goste de ler Capítulo 76 – Gerar a importância do recurso do objeto usando Scikit learn e Random Forest. Se você fez isso, por favor, apoie-nos fazendo uma das coisas listadas abaixo, porque isso sempre ajuda nosso canal.
- Apoie e doe para nosso canal através do PayPal ( paypal.me/Easy2digital )
- Inscreva-se no meu canal e ative o sininho de notificação do canal Easy2Digital no Youtube .
- Siga e curta minha página Página Easy2Digital no Facebook
- Compartilhe o artigo em sua rede social com a hashtag #easy2digital
- Você se inscreve em nosso boletim informativo semanal para receber os artigos, vídeos e códigos de desconto mais recentes da Easy2Digital
- Assine nossa assinatura mensal através do Patreon para aproveitar benefícios exclusivos ( www.patreon.com/louisludigital )
Recomendação do curso Couresa de Ciência de Dados e Aprendizado de Máquina
- Fundamentos da Ciência de Dados
- Estratégia de banco de dados SQL para ciência de dados
- IBM Data Science Básico
- Aprendizado de máquina
- Aprendizado profundo
Perguntas frequentes:
Q1: Qual é o objetivo do produto Gerar?
A: O objetivo do produto Gerar é fornecer uma solução eficiente para a geração de energia limpa e sustentável.
Q2: Quais são as principais características do produto Gerar?
A: O produto Gerar possui as seguintes características principais: alta eficiência energética, baixa emissão de poluentes, fácil instalação e manutenção, e operação silenciosa.
Q3: Como o produto Gerar funciona?
A: O produto Gerar funciona captando a energia do sol e a convertendo em eletricidade por meio de painéis solares fotovoltaicos.
Q4: Qual é a capacidade de geração de energia do produto Gerar?
A: A capacidade de geração de energia do produto Gerar pode variar de acordo com o modelo, mas geralmente é suficiente para suprir as necessidades energéticas de uma residência ou empresa.
Q5: É possível armazenar a energia gerada pelo produto Gerar?
A: Sim, é possível armazenar a energia gerada pelo produto Gerar em baterias ou em sistemas de armazenamento de energia.
Q6: O produto Gerar é adequado para uso residencial?
A: Sim, o produto Gerar é adequado para uso residencial e pode ajudar a reduzir a conta de energia elétrica.
Q7: O produto Gerar requer manutenção regular?
A: Sim, o produto Gerar requer manutenção regular para garantir seu bom funcionamento e eficiência energética. Recomenda-se realizar uma inspeção anual e limpar os painéis solares regularmente.
Q8: O produto Gerar é compatível com a rede elétrica?
A: Sim, o produto Gerar é projetado para ser compatível com a rede elétrica existente, permitindo que a energia gerada seja utilizada na residência ou empresa e, quando necessário, seja fornecida de volta à rede.
Q9: Qual é a vida útil do produto Gerar?
A: A vida útil do produto Gerar pode variar dependendo do modelo e das condições de uso, mas geralmente é de aproximadamente 25 anos.
Q10: O produto Gerar possui garantia?
A: Sim, o produto Gerar possui garantia contra defeitos de fabricação. Consulte o manual do produto ou entre em contato com o suporte técnico para obter mais informações.