
この記事では、価格変更に相関する可能性のある複数の変数を考慮した上で、バリエーション価格を予測する方法を簡単に説明します。この記事を終えると、価格を予測するためのスコアを生成するために Python と Scikit 学習を使用して、このモジュールをビジネスの実際のケースに適用できるようになります。
事前に準備するもの:Numpy、Pandas、Scikit learn、matplotlib、seaborn、Linear Regression、StandardScaler、RandomForest
目次: Python、ScikitLearn を使用した複数の変数に基づくバリアント価格予測
- データセットの読み込み中
- データ探索
- データの前処理
- 線形回帰モデル
- Python、ScikitLearn、線形回帰を使用して価格予測モデルを構築する完全な Python スクリプト
- データ サイエンスと機械学習 Couresa コースの推奨事項
- よくある質問
データセットの読み込み中
この記事では、例としてカリフォルニアの住宅価格データセットを使用します。ビジネスケースデータをデータセットとして使用できると言われています。データセットには、スコアを予測するのに適した一定量のデータが必要であることを確認してください。
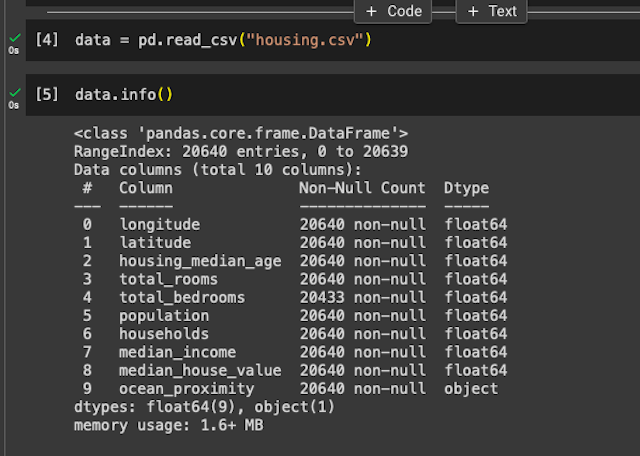
いつものように、Pandas を使用してデータセットをロードし、info() を適用すると、データセットの状態を一目で確認できます。
より適切な予測を行うための主な原則の 1 つは、異なるメトリック間のデータ サイズが同じ量のデータ行を持つ必要があるということです。このサンプルからわかるように、totle_bedrooms メトリクスの列には明らかに NA が示されています。したがって、最初に NA を削除する必要があります。
data.dropna ( inplace= True )データ探索
まず最初に、予測するターゲット バリアントを設定する必要があります。この場合、基本的にこの実験は不動産購入の意思決定を目的としているため、住宅価格の中央値がターゲット バリアントとなります。したがって、既存のテーブルからメトリクスを削除し、ターゲット バリアントをスクリプト内の新しい変数として個別に設定する必要があります。
X = data.drop ([ 'median_house_value' ], axis= 1 )y = data [ 'median_house_value' ]次に、各変数とターゲットのバリアントの相関関係を調査し、データセットが意味があるかどうかの全体像を理解しようとします。

一般に、この目的を達成するためにデータセット全体を使用する必要はありません。この場合、トレーニングのテスト分割を再度活用できます。この方法については、前の章で詳しく説明します。ご興味がございましたら、Easy2Digital.com の他の章をご覧ください。
X_train , X_test , y_train , y_test = train_test_split ( X , y , test_size= 0.2 )次に、join() メソッドと hist() メソッドを使用して、ヒストグラム グラフにそれらを表示してみます。
または、corr() メソッドを使用してヒートマップで表示することもできます。これは、深い色のコントラストと明るい色のコントラストでより視覚的です。
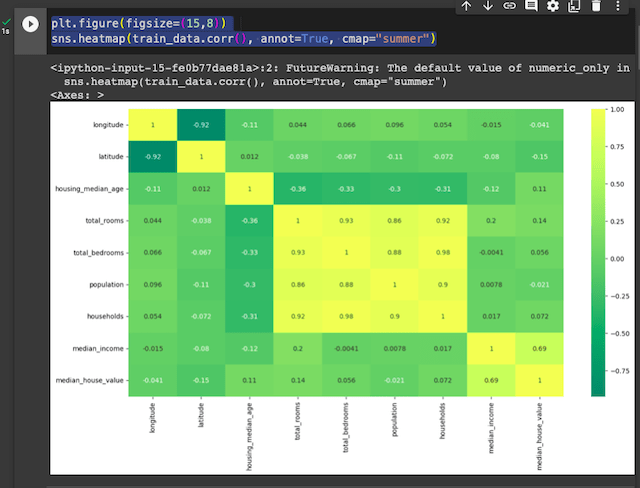
データの前処理
注目の変数が多数表示されます。さらに、上記のヒストグラム分布を見ると、一部の特徴は無意味に見えます。したがって、log() を使用して、注目の変数の分布を改善できるかどうかを確認してみるとよいでしょう。
train_data [ 'total_rooms' ] = np.log ( train_data [ 'total_rooms' ] + 1 )train_data [ 'total_bedrooms' ] = np.log ( train_data [ 'total_bedrooms' ] + 1 )train_data [ 'population' ] = np.log ( train_data [ 'population' ] + 1 )train_data [ 'households' ] = np.log ( train_data [ 'households' ] + 1 )この場合、log メソッドを実装した後では、より意味が分かります。一部の特徴がゼロになる可能性があるため、ログに 1 を加える必要があります。
次に、データ前処理のもう 1 つの重要なセクションは、文字列データ型を整数に変換することです。機械学習は数値駆動のプロセスであり、文字列を直接処理できないためです。
データセットでは、海洋近接度が文字列データ型形式であることがわかります。したがって、パンダの get_dummies メソッドを使用してこれを処理できます。

pd.get_dummies ( train_data.ocean_proximity )線形回帰モデルを使用した予測
これでデータセットが配置されたので、モデルをインポートして、フィーチャ データセットをスケーリングすることによって住宅価格を予測するためのモデルの精度をテストできるようになりました。
from sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import StandardScalerscaler = StandardScaler ()X_train , y_train = train_data.drop ([ 'median_house_value' ], axis= 1 ), train_data [ 'median_house_value' ]X_train_s = scaler.fit_transform ( X_train )reg = LinearRegression ()reg.fit ( X_train_s , y_train )LinearRegression ()test_data = X_test.join ( y_test )test_data [ 'total_rooms' ] = np.log ( test_data [ 'total_rooms' ] + 1 ). test_data [ 'total_bedrooms' ] = np.log ( test_data [ 'total_bedrooms' ] + 1 )test_data [ 'population' ] = np.log ( test_data [ 'population' ] + 1 )test_data [ 'households' ] = np.log ( test_data [ 'households' ] + 1 )test_data = test_data.join ( pd.get_dummies ( test_data.ocean_proximity )) .drop ([ 'ocean_proximity' ], axis= 1 )X_test , y_test = test_data.drop ([ 'median_house_value' ], axis= 1 ), test_data [ 'median_house_value' ]X_test_s = scaler.transform ( X_test )reg.score ( X_test_s , y_test )Python、ScikitLearn を使用して複数の変数に基づいて価格予測モデルを構築する完全な Python スクリプト
Python、ScikitLearn、線形回帰を使用した価格予測モデルの構築に興味がある場合は、 「価格予測モデル」というメッセージを追加してニュースレターを購読してください。 。スクリプトはすぐにあなたのメールボックスに送信されます。
「Python、ScikitLearn、線形回帰を使用した価格予測モデルの構築」を楽しんで読んでいただければ幸いです。もしそうなら、以下にリストされているいずれかの方法で私たちをサポートしてください。それは常に私たちのチャンネルに役立ちます。
- PayPal ( paypal.me/Easy2digital ) を通じて私たちのチャンネルをサポートし、寄付してください。
- 私のチャンネルを購読し、 Easy2Digital Youtube チャンネルの通知ベルをオンにしてください。
- Easy2Digital Facebook ページをフォローして「いいね!」してください
- ハッシュタグ #easy2digital を付けて記. 事をソーシャル ネットワークで共有してください
- Easy2Digital の最新記事、ビデオ、割引コードを受け取るには、毎週のニュースレターに登録してください。
- Patreon を通じて月額メンバーシップに登録すると、限定特典をお楽しみいただけます ( www.patreon.com/louisludigital )
