データの前処理はあらゆるデータ分析プロジェクトの重要な部分ですが、面倒で時間がかかる場合があります。幸いなことに、Numpy 配列スライスを使用することで、この作業をより迅速に完了する方法があります。この記事では、この強力な手法を使用してデータ前処理タスクを高速化する方法を説明します。
目次: Numpy 配列スライスによるデータ前処理の高速化
- Numpy 配列のスライス方法の概要?
- Numpy 配列スライスを使用して結合データを分析し、パフォーマンスを予測する Python スクリプトコード サンプル
- Numpy 配列スライスが AI モジュールのトレーニングに役立つ理由
- Numpy 配列スライスを使用して Tiktok 広告コピーを作成するように AI モジュールをトレーニングするPython スクリプト コード サンプル
- Numpy 配列のスライスについてまとめます
- よくある質問
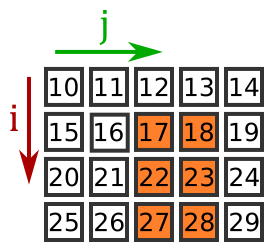
Numpy 配列のスライス方法の概要?
Numpy 配列のスライスは、配列の要素にアクセスするために使用される一般的な方法です。これにより、指定されたインデックスに基づいて配列から要素のサブセットを選択できます。この方法を使用すると、配列に格納されたデータの操作と分析が簡単になります。 Numpy 配列のスライスはデータ分析でよく使用され、より大きな配列からデータのサブセットを選択、変更、分析するために使用できます。また、データの視覚化にも使用でき、データのサブセットを迅速かつ簡単にプロットすることができます。 Numpy 配列のスライスはデータの操作と分析のための強力なツールであり、データ サイエンティストの間で人気のある選択肢です。
Numpy 配列スライスを使用して結合データを分析し、パフォーマンスを予測する Python スクリプト コード サンプル
#import numpy import numpy as np #create numpy array bond_data = np.array([[1.2, 2.3, 3.4], [4.5, 5.6, 6.7], [7.8, 8.9, 9.0]]) #slice the array to get the first two rows first_two_rows = bond_data[:2,:] #slice the array to get the last two columns last_two_columns = bond_data[:,1:] #calculate the mean of the last two columns mean_last_two_columns = np.mean(last_two_columns) #predict the performance of the bond if mean_la. st_two_columns > 5: print("The bond is likely to perform well.") else: print("The bond is likely to perform poorly.")Numpy 配列スライスが AI モジュールのトレーニングに役立つ理由
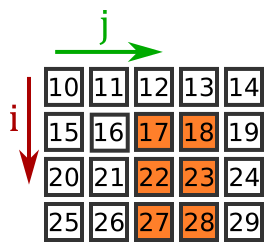
Numpy 配列のスライスは、AI モジュールをトレーニングするための便利なツールです。これにより、AI 開発者は大規模なデータセットをより小さな、より管理しやすい部分に分割できるようになります。これは、AI モジュールの複雑さを軽減するだけでなく、トレーニング プロセスを高速化するのにも役立ちます。Numpy 配列のスライスは、さまざまな方法でデータを操作する柔軟性も提供するため、AI 開発者がモデルを微調整して精度を高めるのに役立ちます。さらに、配列スライシングを使用して特定の AI タスク用にカスタマイズされたデータセットを作成できるため、より集中的なトレーニングが可能になります。最終的に、Numpy 配列のスライスは、プロセスを合理化し、トレーニングをより効率的にするのに役立ちます。
Numpy 配列スライスを使用して Tiktok 広告コピーを作成するように AI モジュールをトレーニングする Python スクリプト コード サンプル
#import numpy import numpy as np #create a numpy array of sample tiktok ads tiktok_ads = np.array(["Hey everyone, check out our new product! #trending #newproduct", "Don't miss out on this amazing deal! #sale #discount", "Follow us for more awesome content! #follow #like", "Share this post with your friends! #share #tagafriend"]) #slice the array to create training and testing sets training_set = tiktok_ads[:3] testing_set = tiktok_ads[3:] #train the AI module using the training set #code omitted #test the AI module using the testing set #code omittedNumpy 配列のスライスについてまとめます
Numpy 配列のスライスは、ユーザーがループを作成せずに配列のセクションをすばやく選択して操作できるようにする強力なツールです。これにより、大量のデータを扱う際に非常に便利で柔軟性が得られます。 Numpy 配列のスライスを使用して、単一の要素、要素の範囲、または要素のサブセットを選択できます。スライス表記を使用して、ストライドとステップ サイズを指定することもできます。Numpy 配列のスライスを使用すると、既存の配列のビューとコピーを作成でき、強力で多用途な機能になります。
