Chapter 16 – Amazon Product Scraper Using Selenium, BeautifulSoup, and Easy2Digital APIs
You might be wondering why some sellers can smell the up-to-trend niche products and make a great investment. Of course, software like Jungle Scout is assisting them to understand the target market consumers. I might partially agree because the most important is the mindset and mastering skills to automate the survey and monitoring. Instead of paying and relying on 3rd party software, self-developed amazon product scraper is indispensable if you like to stand on the front of demand, and monitor your pricing value.

Amazon product information in the search result has great value for you to understand 2 things. They are the sales performance of a product and the customer review on this product and merchant. Then, it can extend to a much wider application, such as the price tracker, and P&L market value.
In this chapter, I would share with you how to create an Amazon product scraper and save the fetched data on Google Sheets. By the end of this chapter, you can learn how to install the gspread module, and where to find the data elements in the HTML.
Table of Contents: Amazon Product Scraper Using Selenium, BeautifulSoup, and Easy2Digital APIs
- Import Selenium, BeautifulSoup module
- Create a Prototype of Product Search Scraper
- Scrape Multi-pages of Search Result
- Save Fetched Dataset to Google Sheets
- Amazon Product Scraper Full Python Script
- FAQ
- AMAZON Latest Trending API Endpoint Recommendation
Amazon Product Scraper – Import Selenium, BeautifulSoup, and gspread Module
It doesn’t allow you to visit the website using BeautifulSoup in a Python script. It would come up as a result of “sorry, something wrong”. Instead, you can smoothly fetch the product data as you like using selenium. Importing these two modules is the same process as previously scripts I did for other bots
Also, this script is not only for fetching and saving product information in a sheet. It also aims to automatically refresh the data in a schedule, and track competitors’ marketing information and product pricing. For the price tracker, I would release another article. Because of that, I would recommend using Google Sheet APIs and managing the data on the Google Sheet. Here I recommend using gspread, because it makes things more simple.
For creating the Google Sheet API and setting up the service account, you can refer to the other article. I released an article previously. For more details, please check out this article.
I would say Easy2Digital Google Sheets API is much easier to connect with Google API and manage fetched data. First thing first, you need to apply for a free Easy2Digital API token
Then, you copy the name of the JSON key you downloaded from your new Google API service account and paste it into the script connected with Easy2Digital API googleJsonparameter.
For more details, please refer to the API documentation
Amazon Product Scraper – Create a Prototype of Product Search Scraper
You can search any product’s information using search queries. Basically, below is the prototype of the Amazon product scraper, whatever product you are searching for. Or wherever Amazon market you are looking through.
1. Amazon Search Query URL structure
You might find that there are two parameters in the URL controlling the SERP. One is the k followed by the keyword. The other is the page followed up with the page number.
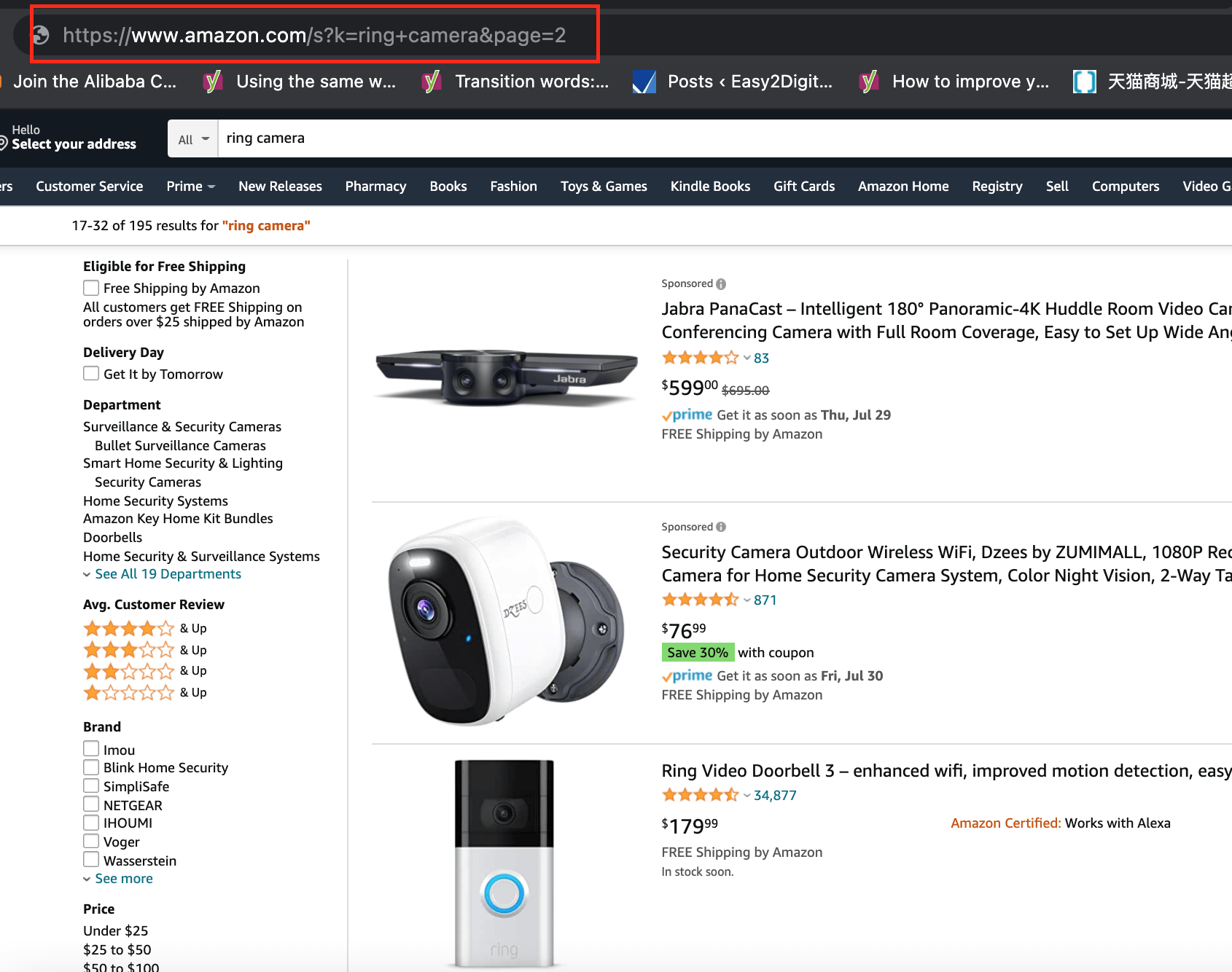
https://www.amazon.com/s?k=ring+camera&page=2
So you can create two variables for the usage later on. One is representing the keyword you are searching for. One is for dynamically looping and fetching more pages
query = "ring+camera"
page = "&page="
2. Find the product information block in the SERP
You can right-click any product title and use the inspect function. You can see what elements can find the entire product information block. The block includes all core product information you aim to fetch. For example, they are ASIN, pricing, title, URL, review count, etc. It’s similar to the web scraping I shared previously.
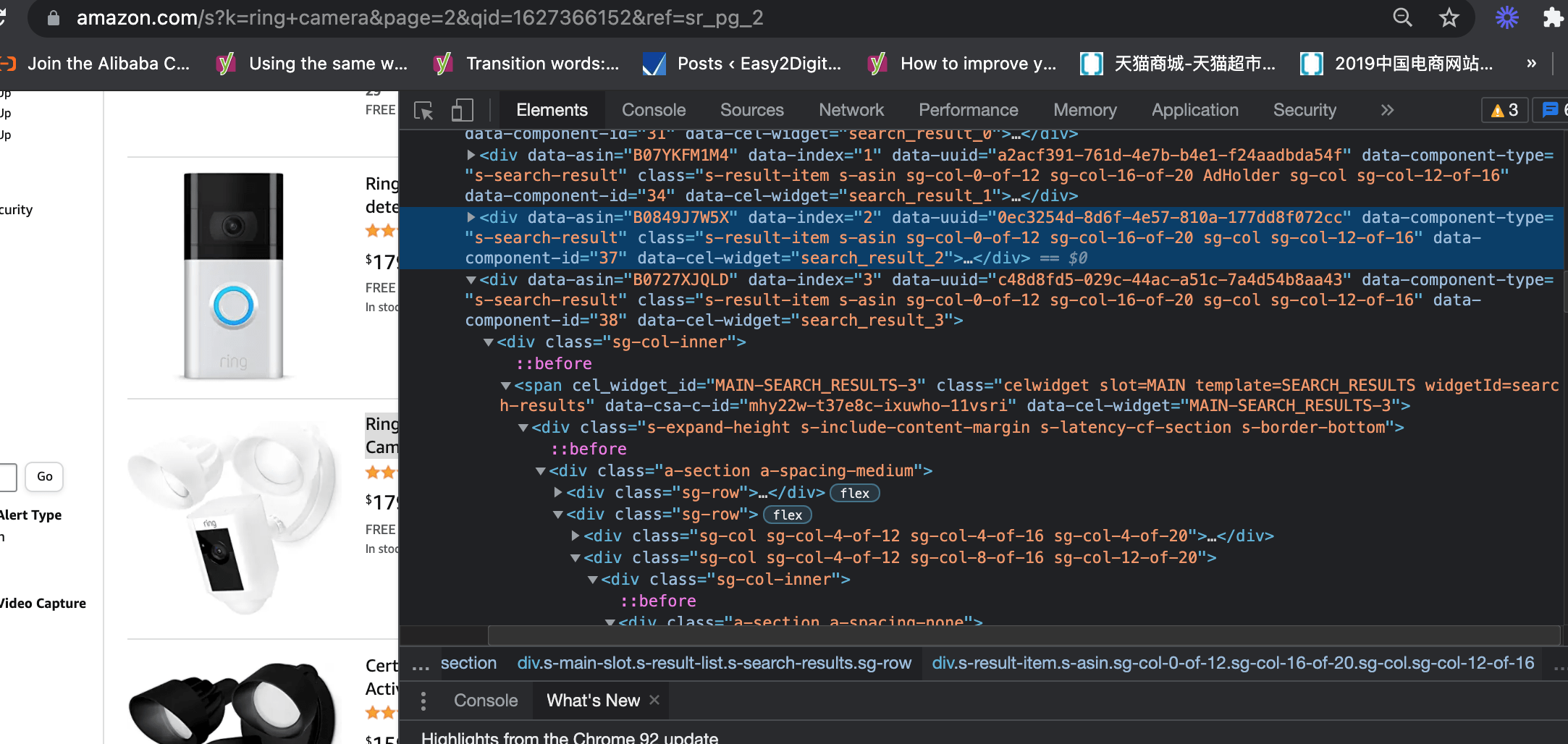
As you can see, all the information sits in a div and a tag named data component type. So you can draft the codes like this. This is for scraping the 1st page
driver.get("https://www.amazon.com/s?k=query
soup = BeautifulSoup(driver.page_source, 'html.parser')
results = soup.find_all('div',{'data-component-type': 's-search-result'})
3. Select the Data Type and Scrape Specifically
ASIN is a key element you must fetch because the price tracker needs this element to connect with your current P&L calculator. I would talk about this in the other article.
As you can see, the ASIN value is sitting in this tag data-asin. So you can create a variable and use attrs to get each product’s ASIN number
asins = item.attrs['data-asin']
Then, the product title is the h2 in the HTML. So the python code can be like this. However, for removing any removes any leading (spaces at the beginning) and trailing (spaces at the end) characters, you can use strip() after the text
try:
title = item.h2.a.text.strip()
except Exception as e:
raise None
Pricing is another key element in the price tracker because it’s dynamic and might change depending on your competitor’s promotion. So in the Amazon product scraper, this coding can help you fetch the pricing. However, for filtering and calculating market value later, I would recommend you remove the currency signal. This is to ensure the data is in the number format in the Google Sheets.
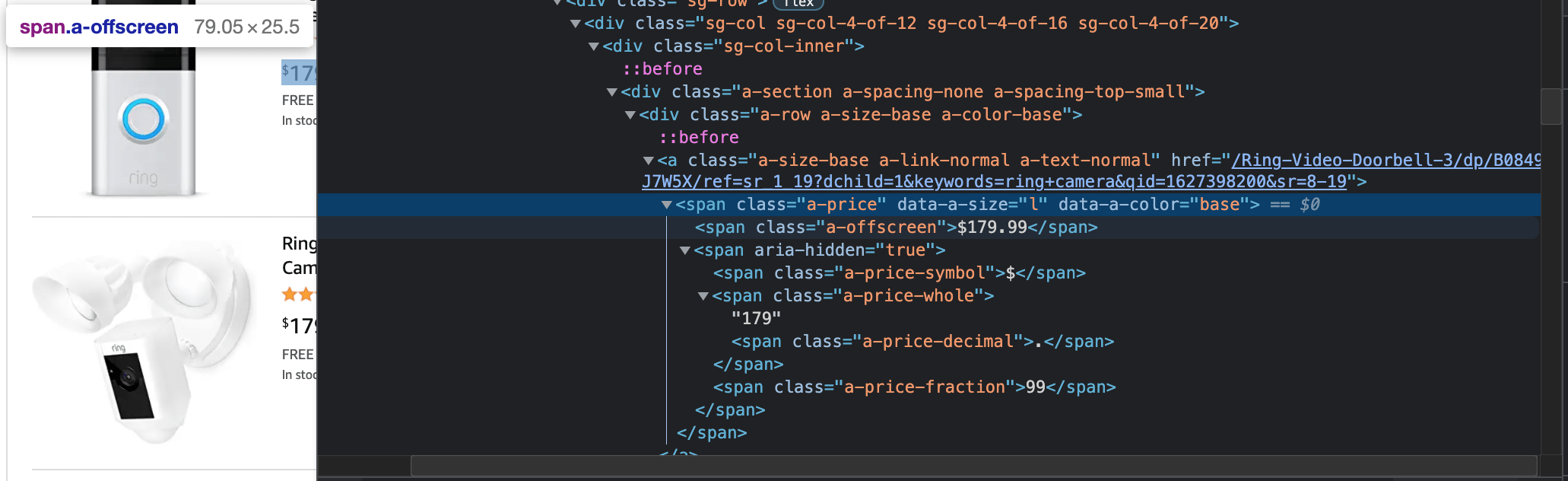
try:
price_parent = item.find('span','a-price')
price = price_parent.find('span','a-offscreen').text.replace('$','')
except Exception as e:
price_parent = '0'
price = '0'
Amazon Product Scraper – Scrape Multi-pages of Search Result
The 1st page of Amazon SERP has avg.22 pieces of product. It might not be sufficient for you to understand a product’s market performance and opportunity. In this case, you need to scrape more than one page. Luckily it’s not complicated, and it’s similar to the web pagination scraper I shared before.
First thing first, you need to create a loop on the higher tier than the specific data fetch looping. You can create a variable X.
Then, in the range, you can set the number of pages. But please keep in mind that the last page should be y – 1. For example, here the last page is 3, so it means the last page is 2.
for x in range (1,3):
driver.get("https://www.amazon.com/s?k="+query+page+str(x))
soup = BeautifulSoup(driver.page_source, 'html.parser')
results = soup.find_all('div',{'data-component-type': 's-search-result'})
for item in results:
asins = item.attrs['data-asin']
Last but not least, as you know the Amazon URL structure, we need to update the URL request, which is like this.
driver.get("https://www.amazon.com/s?k="+query+page+str(x))
Save Fetched Data to the Google Sheets
Now things are ready, and it’s time to feed and save in the Google Sheet. You need to use “POST” method and add the fetched data and specific sheet tab with cell position as two variables respectively to the Easy2Digital API parameter
Full Python Script of Amazon Product Scraper
If you would like to have the full version of the Python Script of Amazon Product Scraper, please subscribe to our newsletter by adding the message “Chapter 16”. We would send you the script immediately to your mailbox.
I hope you enjoy reading Chapter 16 – Amazon Product Scraper Using Selenium, BeautifulSoup, and Easy2Digital APIs. If you did, please support us by doing one of the things listed below, because it always helps out our channel.
- Support and donate to our channel through PayPal (paypal.me/Easy2digital)
- Subscribe to my channel and turn on the notification bell Easy2Digital Youtube channel.
- Follow and like my page Easy2Digital Facebook page
- Share the article to your social network with the hashtag #easy2digital
- Buy products with Easy2Digital 10% OFF Discount code (Easy2DigitalNewBuyers2021)
- You sign up for our weekly newsletter to receive Easy2Digital latest articles, videos, and discount codes
- Subscribe to our monthly membership through Patreon to enjoy exclusive benefits (www.patreon.com/louisludigital)
FAQ:
Q1: What is Amazon Product Scraper?
A: Amazon Product Scraper is a tool designed to extract product data from Amazon’s website. It allows users to gather information such as product titles, prices, descriptions, images, and reviews from Amazon’s listings.
Q2: How does Amazon Product Scraper work?
A: Amazon Product Scraper works by utilizing web scraping techniques to extract data from Amazon’s website. It navigates through product pages, collects the desired information, and stores it in a structured format for further analysis or use.
Q3: What can I do with the data extracted by Amazon Product Scraper?
A: The data extracted by Amazon Product Scraper can be used for various purposes. Some common use cases include price comparison, market research, competitor analysis, inventory management, and product catalog creation.
Q4: Is it legal to scrape data from Amazon?
A: While web scraping itself is not illegal, scraping data from Amazon may violate their terms of service. It is important to review and comply with Amazon’s policies when using any scraping tool or extracting data from their website.
Q5: Is Amazon Product Scraper suitable for large-scale scraping?
A: Yes, Amazon Product Scraper is designed to handle large-scale scraping tasks. It supports concurrent scraping, proxy rotation, and efficient data extraction techniques to ensure optimal performance even when dealing with a large number of product listings.
Q6: Does Amazon Product Scraper require any coding knowledge?
A: No, Amazon Product Scraper is a user-friendly tool that does not require any coding knowledge. It provides a simple and intuitive interface for configuring scraping settings, managing proxies, and exporting data.
Q7: Can I scrape specific categories or niches using Amazon Product Scraper?
A: Yes, Amazon Product Scraper allows you to specify the categories or niches you want to scrape. You can filter products based on various criteria such as keywords, price range, ratings, and more to ensure you extract only the relevant data.
Q8: Is Amazon Product Scraper compatible with different operating systems?
A: Yes, Amazon Product Scraper is compatible with multiple operating systems including Windows, Mac, and Linux. It is a web-based tool accessible through a browser, so you can use it on any device with an internet connection.
Q9: How frequently is Amazon Product Scraper updated?
A: Amazon Product Scraper is regularly updated to ensure compatibility with any changes or updates Amazon makes to their website. The development team works diligently to provide users with a reliable and up-to-date scraping tool.
Q10: Is there any support available for Amazon Product Scraper?
A: Yes, customer support is available for Amazon Product Scraper. You can reach out to the support team for any inquiries, technical issues, or assistance with using the tool.
Amazon API Endpoint Recommendation

Keyword Data Estimator API
Price: US$54
Keyword data estimator can generate keyword avg.monthly traffic and CPC. Keyword estimator can generate the keyword data by country and channel using a keyword query. Options of search engine channel include Google, Bing, Amazon. 4 languages are doable which are English, Japanese, Simplified Chinese and Traditional Chinese
More API options from the Amazon collection.



I’m definitely happy I discovered it and I’ll
be book-marking it and checking back frequently!