Chapter 2: Web Scraping with BeautifulSoup, Requests, Python
In the previous Python tutorial for digital marketers 1, we discussed what a digital marketer can benefit from Python super power, why she or he needs it, and how to install and set up the latest Python version for Mac OS. As you might be aware, one of the most essential Python benefits to digital marketers is to scrape web data and update the data automatically.
So in this article, I’ll talk about how to set up an environment to write python scripts for the purpose of scraping objective website data. This article doesn’t go into details regarding Python methods introduction, code writing and feeding the data to a spreadsheet or database. I’ll release other articles and videos to walk through. But the purpose of this article is to let you understand the big picture of what components are necessary and how it works.
By the end of this article, you can master the installation of beautifulsoup4, requests, lxml, html5lib and sublime text, and how to scrape web data by them.

In the previous Chapter 1, we discussed how a digital marketer can benefit from Python superpowers. We learned why she or he needs it, and how to install and set up the latest Python version for Mac OS. As you might be aware, one of the most essential Python benefits to digital marketers is to scrape web data and update the data automatically.
So in this Python Tutorial, I’ll talk about how to set up an environment to write python scripts for the purpose of scraping objective website data. This article doesn’t go into details regarding Python methods introduction, code writing, and feeding the data to a spreadsheet or database. I’ll release other articles and videos to walk through. But the purpose of this article is to let you understand the big picture. You can learn what components are necessary and how it works.
By the end of this Chapter, you can master the installation of beautifulsoup4, requests, lxml, html5lib, and sublime text. And you can learn how to scrape web data from them.
Table of Contents: Web Scraping with BeautifulSoup, Requests, Python
BeautifulSoup4
Beautiful Soup is a library that makes it easy to scrape information from web pages. It sits atop an HTML or XML parser, providing Pythonic idioms. They are for iterating, searching, and modifying the parse tree.
Installing Beautifulsoup4 is not complex, below are the steps
1. Go to Pypi.org and download the latest version beautifulsoup4-4.9.3
2. Open the Mac terminal, and input
cd Desktop
(Note: Desktop means the beautifulsoup4 file location you save)
cd beautifulsoup4-4.9.3
sudo python3 ./setup.py install
3. Check if you install beautifulsoup4 successfully
Input: pip3 install beautifulsoup4. If the return value is a requirement already satisfied, that means the installation is done.
Once it’s installed, we need to make sure we have parsers to parse the HTML. Parsers are essential to scrape the data and get the correct return result. Basically, it’s because the objective HTML page information matters. If the target page structures are built in a perfect form, there is no difference between the parsers. But if the target page structures have mistakes, different parsers can fill in the missing information differently and ensure the return result is correct.
In BeautifulSoup4 documentation, there is a section that explains the difference among parsers. But basically, they suggest installing and using the lxml parser and html5lib parser. So here I show how to install it in a Mac terminal:
Pip3 install lxml
Pip 3 install html5lib
Requests
You can use Requests to easily make HTTP or HTTPS requests. It’s because it is a Python library. Basically, its primary purpose is to call the objective data and show it on your screen by running a Python script. It is functioning as you type in a URL on a browser to open the page. Generally, Requests have two main use cases, making requests to an API and getting raw HTML content from websites (i.e., scraping).
Install Requests is pretty easy, below are the steps
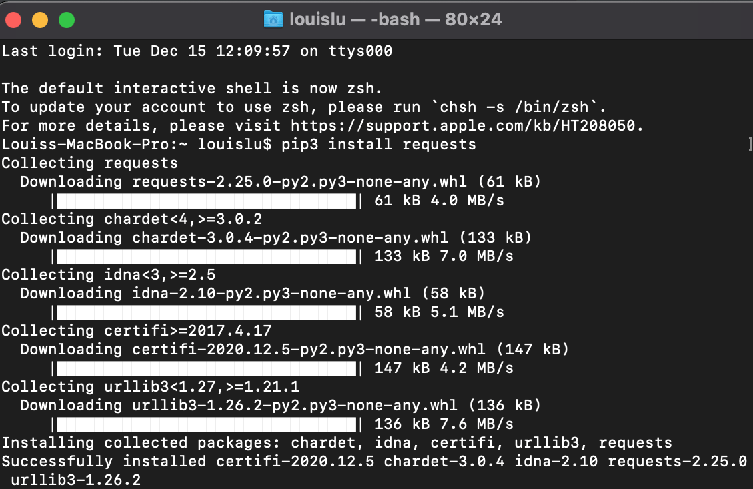
- Open the Mac Terminal.
- Input: pip3 install requests. Please remember to use pip3 if you haven’t created the alias between your Mac Python version. And the latest Python3 version which I use here as an example. Otherwise, it might cause installation on the wrong folder path.
- Wait and see if Requests are successfully installed, which includes the date and related version information.
Sublime Text Editor
Sublime Text is a shareware cross-platform source code editor with a Python application programming interface (API) for free. It natively supports many programming languages and markup languages. And the functions can be added by users with plugins, typically community-built and maintained under free software licenses.
There are lots of available free editors such as atome, etc. You can use another similar software if you already have one. I’ll take sublime text as an example to walk you through how to use it to create scripts and scrape web data.
1. Check the build system and update the latest Python
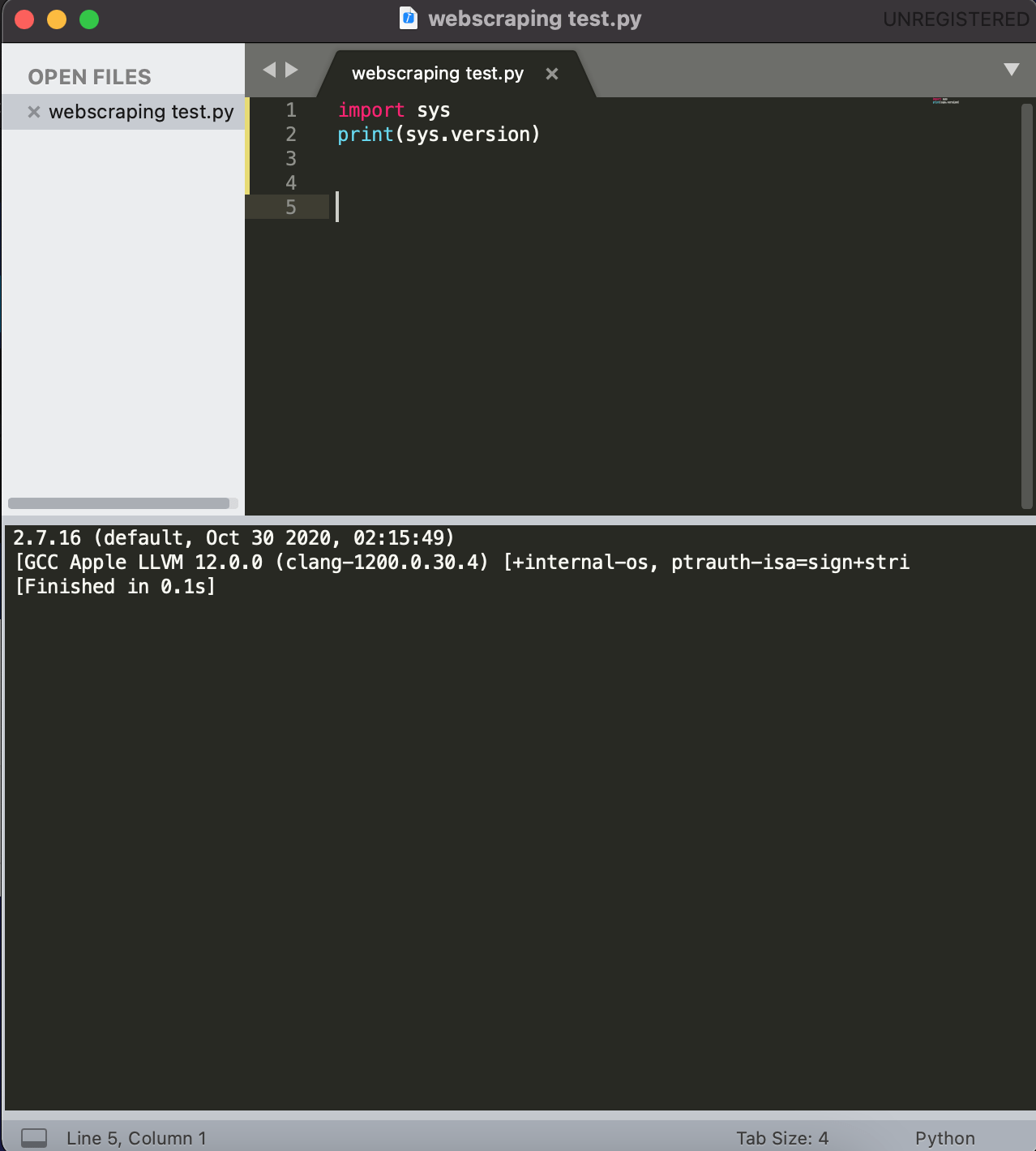
In Sublime text, if you go to tools and build systems, you can find many programming language options available, including Python. However, the default Python version might not be updated. As you can see from the below screencap, we select Python and input a single line code, and it shows Python 2.7, instead of the latest Python3
Import sys
print(sys.version)
Photo 1
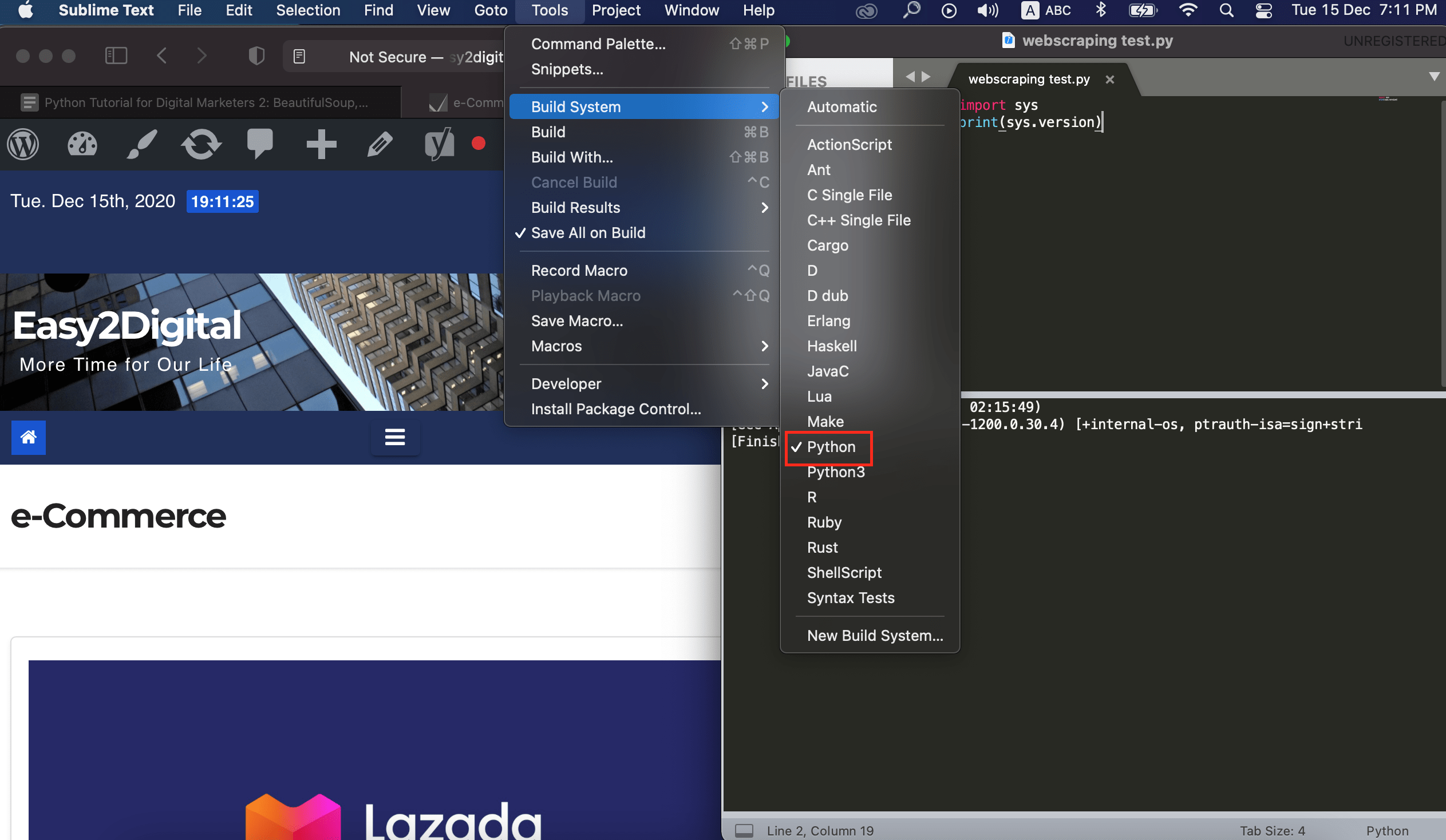
Photo 2
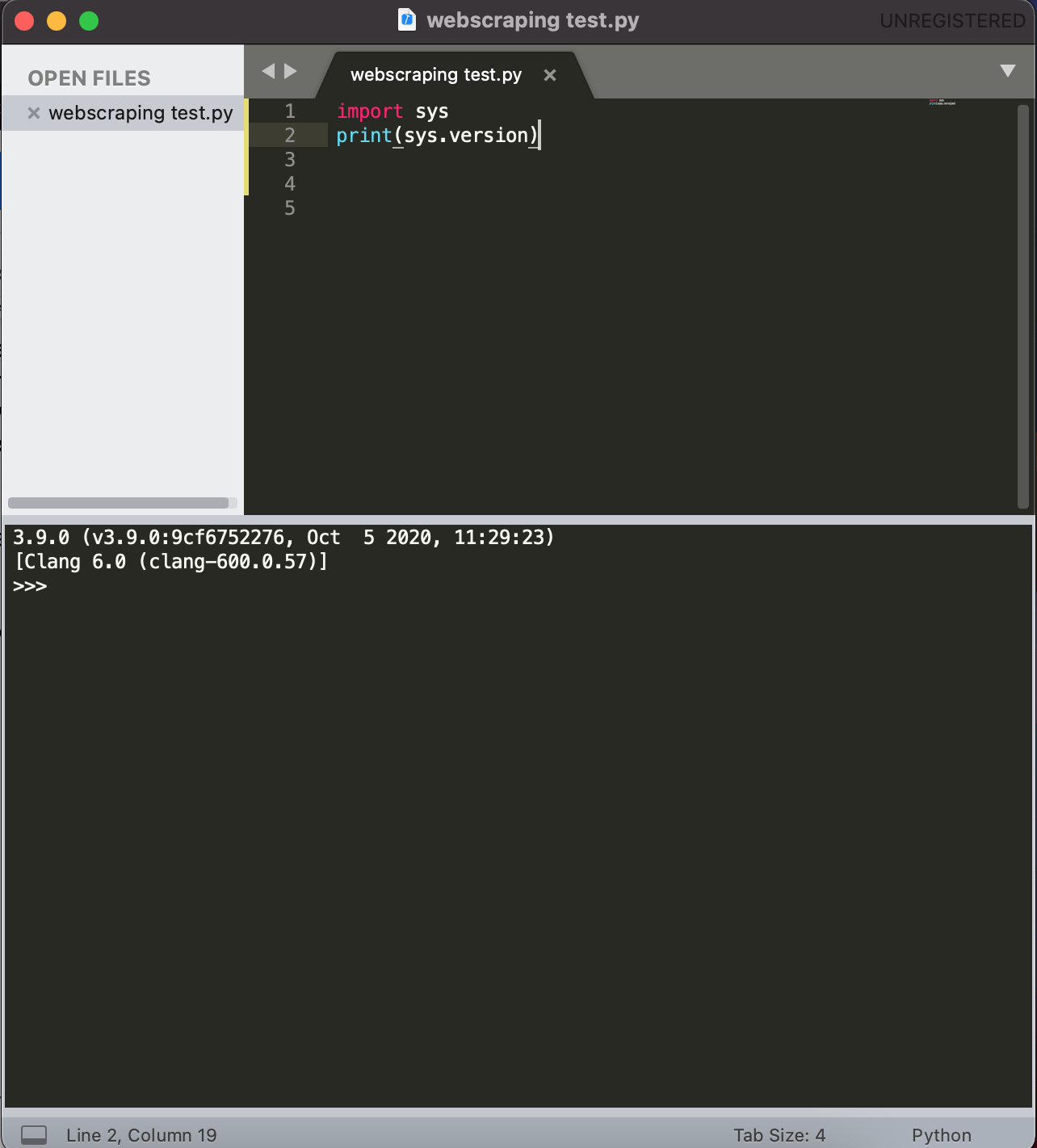
2. Add a new Python3 build system
Adding a build system and the script shows a line of code:
“Shell_cmd”: “make”
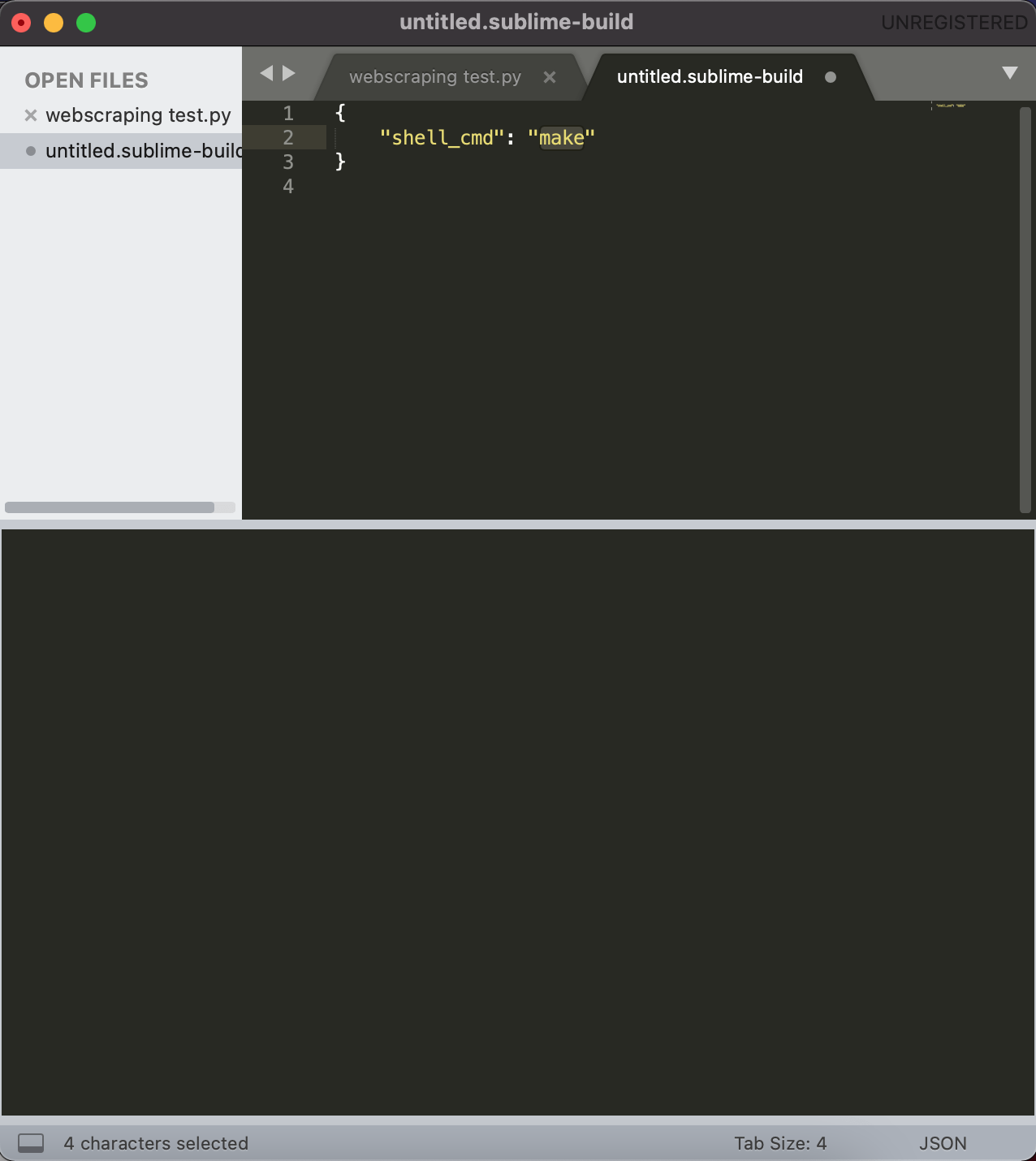
Replace it with the codes below and save. Now you have installed the latest Python3 version, and you can check by inputting import sys, print(sys. version)
"cmd": ["python3", "-i", "-u", "$file"],
"file_regex": "^[ ]File \"(...?)\", line ([0-9]*)",
"selector": "source.python"
Photo 1
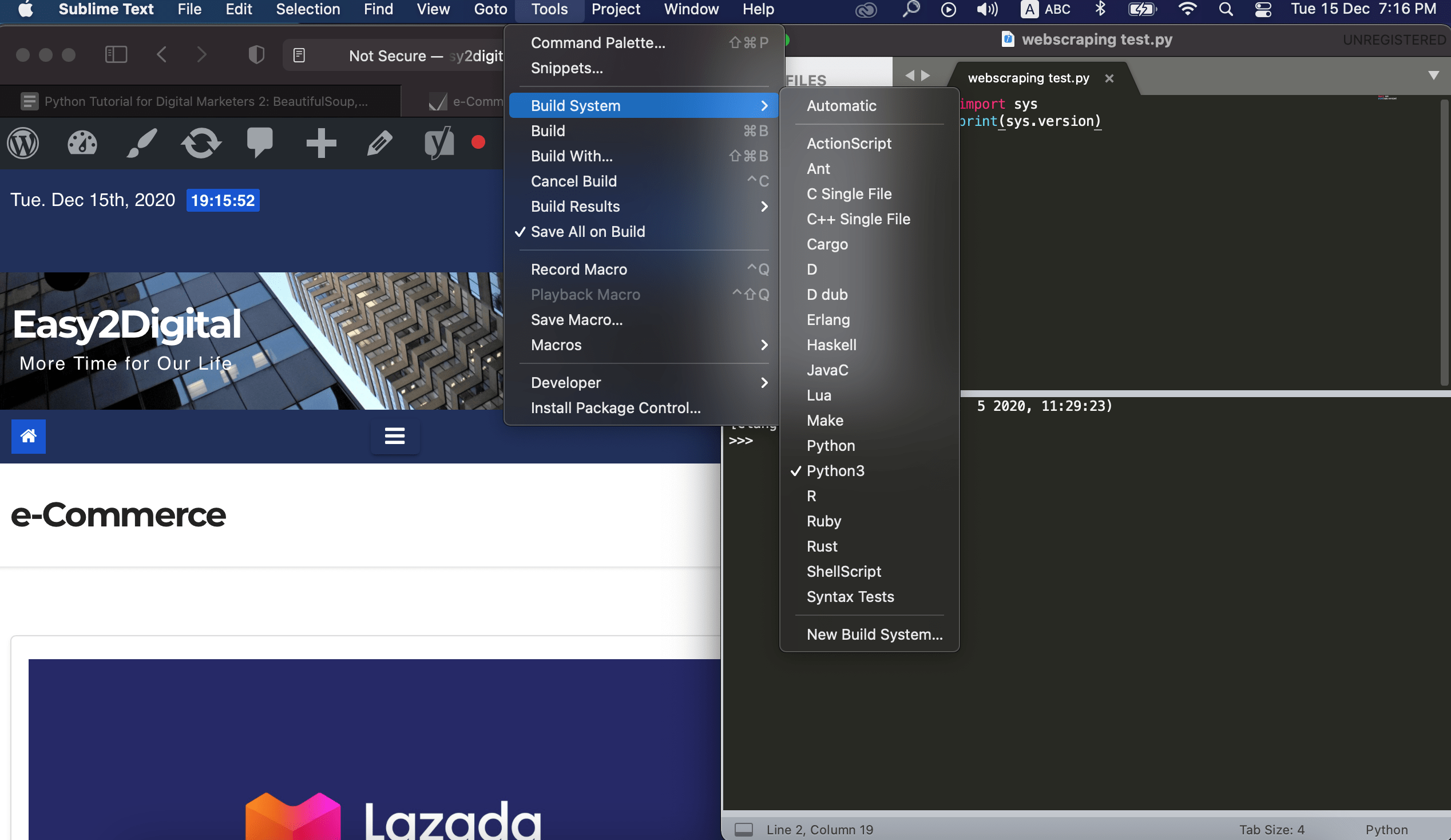
Photo 2
Web Scraping Case:
(www.easy2digital.com/topics/ecommerce/)
Things are ready now, and we can test web scraping in Sublime.
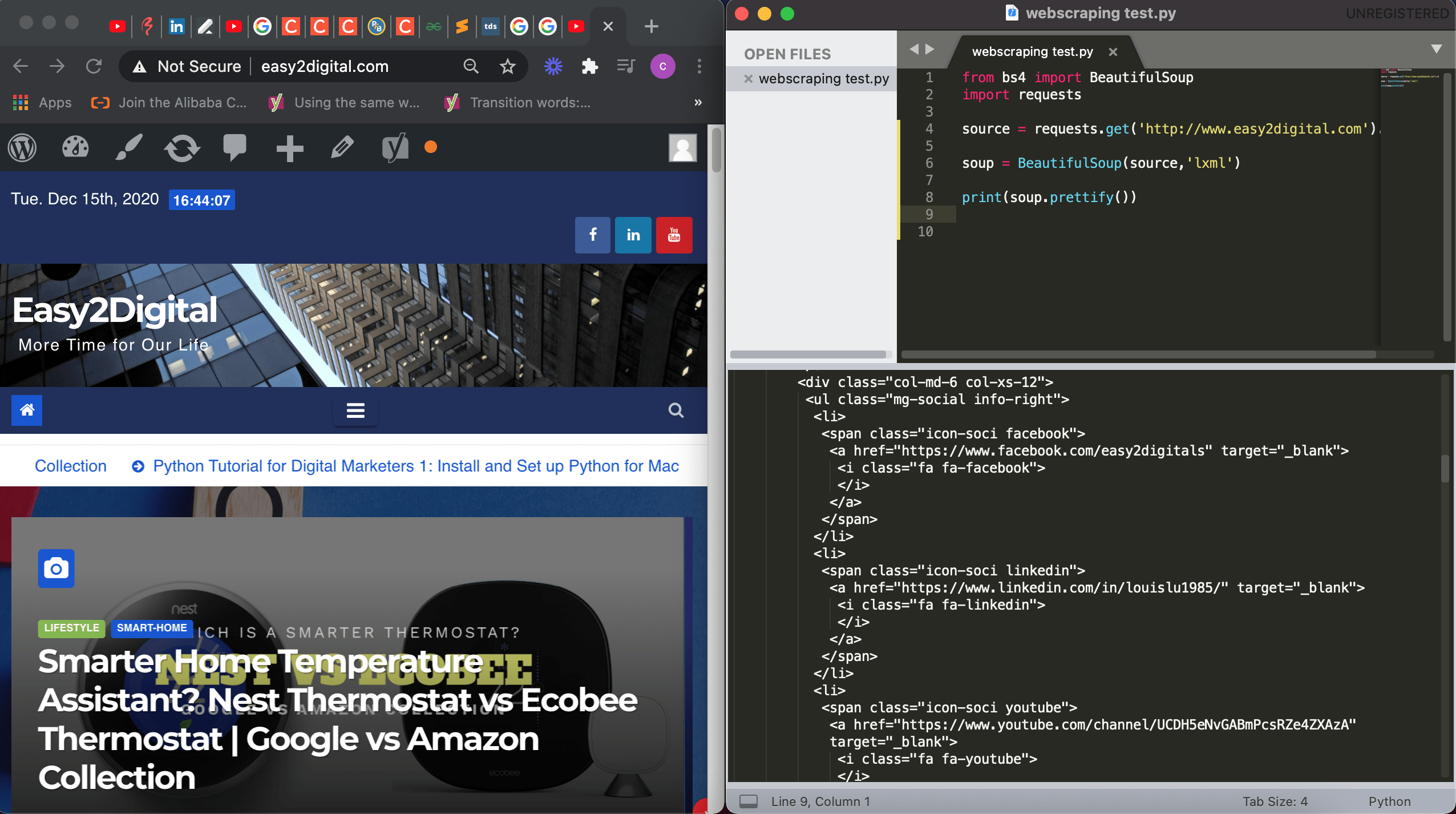
First of all, we need BeautifulSoup and requests, so let’s start by inputting
from bs4 import BeautifulSoup
import requests
And then below is a variable that requests to get HTML source text data of my website eCommerce article section
source = requests.get('https://www.easy2digital.com/topics/ecommerce/').text
Then, we can parse this source code information into BeautifulSoup and print it out.
soup = BeautifulSoup(source,'lxml')
print(soup.prettify())
Last but not least, we input command B to run the coding and as you can see, all source codes of the page are generated. This data is still not helpful because we need to create lines of code to specifically scrape the division data that we need.
Being said that, a Web scraping environment by a sublime text editor is already working, and the thing is that we aim to scrape and write the codes based on the objective in a sublime text editor.
I hope you enjoy reading Chapter 2: Web Scraping with BeautifulSoup, Requests, Sublime Text. If you did, please support us by doing one of the things listed below, because it always helps out our channel.
- Support and donate to our channel through PayPal (paypal.me/Easy2digital)
- Subscribe to my channel and turn on the notification bell Easy2Digital Youtube channel.
- Follow and like my page Easy2Digital Facebook page
- Share the article on your social network with the hashtag #easy2digital
- Buy products with Easy2Digital 10% OFF Discount code (Easy2DigitalNewBuyers2021)
- You sign up for our weekly newsletter to receive Easy2Digital latest articles, videos, and discount codes
- Subscribe to our monthly membership through Patreon to enjoy exclusive benefits (www.patreon.com/louisludigital)
If you are interested in chapter 3, please check out the article below
Chapter 3: Utilise CSV Module to Write, Parse, Read CSV Files to Manage Scraped Data
FAQ:
Q1: What is web scraping?
A: Web scraping is the process of extracting data from websites using automated tools or software.
Q2: Why is web scraping important for eCommerce?
A: Web scraping allows eCommerce businesses to gather valuable data on competitors, prices, product information, customer reviews, and more, which can be used for market research and strategic decision-making.
Q3: What are the benefits of using web scraping for eCommerce SEO?
A: Web scraping can provide insights into keyword rankings, competitor strategies, search volume, and other SEO-related data, helping businesses optimize their eCommerce websites for better search engine visibility.
Q4: Is web scraping legal?
A: Web scraping is a legally gray area and can vary depending on the website’s terms of service and the jurisdiction. It’s important to ensure compliance with applicable laws and respect the website’s policies during web scraping.
Q5: How can web scraping help with product pricing?
A: Web scraping can monitor competitor pricing, allowing eCommerce businesses to adjust their own prices accordingly and stay competitive in the market.
Q6: What are some popular web scraping tools for eCommerce?
A: Some popular web scraping tools for eCommerce include BeautifulSoup, Scrapy, Octoparse, and Import.io.
Q7: How can web scraping improve product descriptions?
A: Web scraping can provide access to product descriptions from various sources, helping businesses create unique and informative content that stands out to both search engines and customers.
Q8: Can web scraping be used to monitor customer reviews?
A: Yes, web scraping can be used to extract customer reviews from multiple platforms, allowing businesses to analyze feedback and improve their products or services.
Q9: What precautions should be taken while web scraping?
A: When web scraping, it’s important to respect the website’s bandwidth limitations, avoid excessive requests, use proxies if necessary, and comply with any anti-scraping measures put in place by the website.
Q10: How can web scraping help with competitor analysis?
A: Web scraping can gather data on competitor pricing, product offerings, marketing strategies, and more, providing valuable insights for businesses to refine their own eCommerce strategies.



In this tutorial, we notice that there is a collection we should pay attention to, where we thought it just talked about how to install…! This collection is the easiest and simplest tutorial to learn and apply to the work so far.