
In the previous chapter, I walked you through how to scrape potential Instagram partners by using hashtags and selenium. Basically, you are able to collect a list of hundreds of candidates by just spending 10 mins. Of course, this will not be the ending. It’s because learning trending content, monitoring your competitor’s latest activities, and automating communication must be the next step.
So in this chapter for digital marketers, I would walk you through two methods to collect Instagram user profile data. One is to continue using selenium arguments and syntax. The other is to use Beautifulsoup and JSON, apart from Selenium. By the end of this article, you can learn the logic to write the script, and of course, collect all the information in a single excel sheet.
Table of Contents: Build an Instagram Profile Scraper to Scrape Instagram Email, Followers, Posts, and More
- Open and Read the Fetched Links in a CSV File
- Method of Selenium find_element_by_xpath argument
- Use Selenium, BeautifulSoup, and JSON method
- Full Python Script of Instagram Email Scraper
- FAQ
- INSTAGRAM Latest Trending API Endpoint Recommendation
Instagram Profile Scraper – Open and Read the Fetched Links in a CSV File
In the previous Python Tutorial, we saved all the fetched Instagram hashtag’s post links, post likes, and the user’s IG profile link. So you can reuse the CSV file, and generate all the Instagram user profile links you are going to scrape.
Here are the codes to read the links. csv_reading [1] means the second column in the sheet is your scraping objective. It’s because 0 represents the first and 1 represents. the second in computer science.
with open('dafdsfere.csv','r') as csv_file:csv_reading = csv.reader(csv_file)print(csv_reading[1])In the sublime text, it represents working if you can print csv_reading and see the result of this KOL profile list.
Being said that, I am not going to highlight how to use selenium to login into your Instagram account and scrape. If you are interested in it, please check out the previous article of Chapter 12.
Instagram Profile Scraper – Method of Selenium find_element_by_xpath Argument
Now it’s time to scrape the data we want. First thing, we need to create a loop and only click through the column. Then, you can use selenium syntax to open the links. Below are the codes
for line in csv_reading:links = line[1]try:Page = driver.get(links)except Exception as e:Page = Nonetry:Secondly, you can inspect the object and copy the XPath. It’s for the purpose to lock the position and fetch the objective data. It’s the same as our previous approach.
Take the posts and followers for example. Post-XPath and follower XPath are listed below
//*[@id="react-root"]/section/main/div/header/section/ul/li[1]/span/span//*[@id="react-root"]/section/main/div/header/section/ul/li[2]/a/spanSo we can use find_element_by_xpath to fetch the data and use the text syntax to get the numbers.
PostNumber = driver.find_element_by_xpath('//*[@id="react-root"]/section/main/div/header/section/ul/li[1]/span/span')PostNumber2 = PostNumber.textFollowerNumber = driver.find_element_by_xpath('//*[@id="react-root"]/section/main/div/header/section/ul/li[2]/a/span')FollowerNumber2 = FollowerNumber.textLast but not least, you need to append the data and generate a CSV file by using pandas. For more details, please check out the chapter 12 article.
Instagram Profile Scraper – Use Selenium, BeautifulSoup, and JSON method
The cons in the above section are you can’t find the email element. It’s because only the mobile version shows the email contact button. And not all of the users show the email address in their profile.
For easier fetching user data, you can refer to Instagram JSON. This approach is very similar to fetching the Shopify product data we discussed previously.
Adding ?__a=1 behind Instagram’s user profile URL can show you the JSON data structure. I take this IG user for example. Basically, you can find what elements are open to access via API JSON. For example, they are emails, posts, followers, photos, external URLs, etc.
https://www.instagram.com/sophieapps/?__a=1&__d=dis
Regarding the Python script, the lines of coding are very similar to fetching by using the selenium find by XPath method. It’s different after defining the looping section.
Core lines of coding
First of all, you need to click through the URL links with additional parameters. So then, you need to convert the source code into an organized JSON format by using beautiful soup and JSON. Here are the codings
for line in csv_reading:links = line[1]page = driver.get(links + "?__a=1")soup = BeautifulSoup(driver.page_source, "html.parser").get_text()jsondata = json.loads(soup)Then, it’s very similar to fetching Shopify product data. You need to find the path of each element of data you aim to fetch, and then create the codings. Below is an example to fetch the biography data.
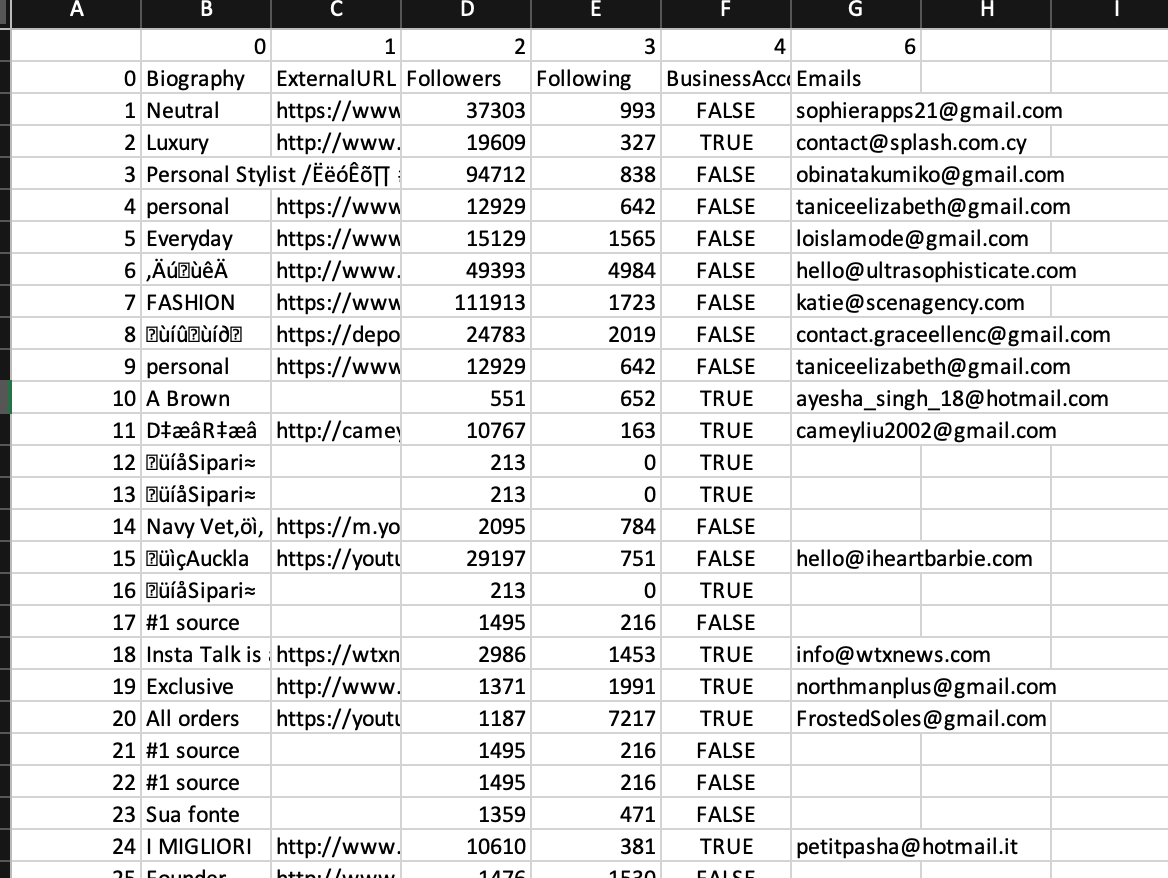
biography = jsondata["graphql"]["user"]["biography"]Last but not least, you can print a biography to see if it’s working. If it’s working, you can append the column data and save it as a CSV file. Here is a sample if you use the codings and generate the fetch data.
Full Python Script of Instagram Profile Scraper
If you would like to have the full version of the Python Script of Instagram Email Scraper, please subscribe to our newsletter by adding the message “Chapter 13”. We would send you the script asap to your mailbox.
I hope you enjoy reading Chapter 13 – Build an Instagram Profile Scraper to Scrape Instagram Email, Followers, Posts, and More Using Selenium, BeautifulSoup, and JSON. If you did, please support us by doing one of the things listed below, because it always helps out our channel.
- Support and donate to my channel through PayPal (paypal.me/Easy2digital)
- Subscribe to my channel and turn on the notification bell Easy2Digital Youtube channel.
- Follow and like my page Easy2Digital Facebook page
- Share the article on your social network with the hashtag #easy2digital
- You sign up for our weekly newsletter to receive Easy2Digital latest articles, videos, and discount code
- Subscribe to our monthly membership through Patreon to enjoy exclusive benefits (www.patreon.com/louisludigital)